 (see graphic, 60K).
(see graphic, 60K).
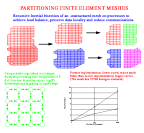
Objective: Partitioning an unstructured finite element mesh among the processors of a parallel supercomputer concurrently to set the stage for the finite element analysis. The domain partition achieves load balance, preserves proper data locality and reduces communications during the solution of the problem.
Approach: The element centroids are partitioned using an inertial recursive bisection algorithm, and then nodes and elements are migrated accordingly. In design and implementation, we pay particular attention to (a) using scalable algorithms so that the partitioner performs well on very large number of processors (b) complete flexibility to handle any type of finite elements, discontiguous sequential labelings and unsorted existing mesh data. (see graphic, 60K).
Accomplishments:
The library of (a) and tool of (b) could be stand-alone software and thus have been delivered to JPL HPCC/ESS Software Repository.
Significance: Finite element analysis is used in broad, diverse areas such as analysis and designed of automobile body-frame, electromagnetic devices, airplane exteriors, etc. The ever-increasingly larger and complex geometries must be dealt in a parallel super-computer. Parallel mesh partitioner sets up the necessary environment for the problem to be calculated there.
Status/Plans: The partitioner is written, debugged, and fully tested on a variety of finite element meshes. The partitioner exhibits a good (logarithmic) scaling character, i.e., partitioning a problem 8 times larger on 8 times more processors only takes twice as longer time.
Point of Contact:
 Return to the PREVIOUS PAGE
Return to the PREVIOUS PAGE