| Home: semmix.homepage.com |
| Home: semmix.homepage.com |
| goto: english version |
| Formaty zbior≤w HEX | IntelHEX uproszczony | IntelHEX og≤lny | IntelHEX mutacje | S-Record uproszczony | S-Record og≤lny | TekHex | Tektronix HEX | MosTech |
Formaty zbior≤w HEX
Dane przeznaczone do wpisania do pamiΩci EPROM, PROM, itp. mog▒ byµ zakodowane na kilka sposob≤w. Jest kilka typ≤w zbior≤w z przeznaczeniem dla tego rodzaju danych. Zbiory s▒ produkowane przez LINKERy, DEBUGGERy lub mog▒ byµ wytwarzane przez specjalne programy konwertuj▒ce lub odczytuj▒ce zawarto╢µ pamiΩci EPROM. Og≤lnie, taki zbi≤r zawiera tre╢µ odczytan▒ lub tre╢µ, kt≤ra ma byµ zapisana do pamiΩci.
Zbiory BIN:
Najprostrzym przypadkiem mo┐e byµ to zbi≤r okre╢lany jako binarny i na og≤│ rozszerzeniem nazwy zbioru jest: ".BIN". Zwyk│y zbi≤r binarny to zwyk│y obraz pamiΩci zapisany w pliku. Takie zbiory s▒ rzadziej stosowane, ale te┐ s▒ w u┐yciu.
Zbiory HEX:
Bardziej powszechnie stosowane s▒ zbiory ze specjalnie zakodowan▒ tre╢ci▒ binarn▒ za pomoc▒ znak≤w ASCII (American Standard Code for Information Interchange). Format ich jest nazywany: HEXADECIMAL. Posiadaj▒ budowΩ zwyk│ych plik≤w TXT. To znaczy plik z│o┐ony jest z rekord≤w (linii, - wierszy tekstu), zako±czonych EOL (CR+NL lub samo NL w unix). WnΩtrze rekordu ma znaki zgodne ze standardem i interpretacj▒ ASCII. Jeden rekord zawiera zakodowan▒ PORCJ╩ - fragment obrazu pamiΩci, oraz informacje takie jak: d│ugo╢µ porcji, oraz adres pocz▒tku dla porcji w przestrzeni adresowej pamiΩci. Albo jest rekordem organizacyjnym. Taki spos≤b pozwala na opis zawarto╢ci nie koniecznie dla ca│ej pamiΩci. Rekordy nie musz▒ opisywaµ kolejnych fragment≤w pamiΩci w spos≤b ci▒g│y.
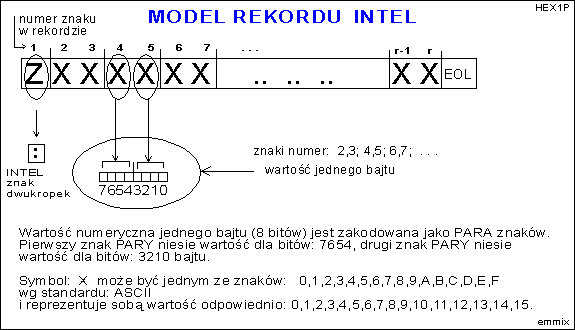
Og≤lny model typu INTEL:
Og≤lny model S-RECORD Motorola:
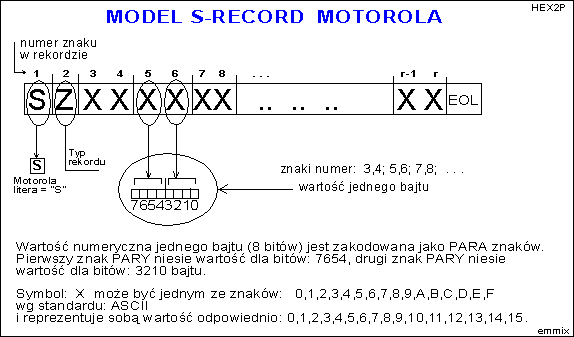
Istniej▒ pewne odstΩpstwa od powy┐szych modeli. S▒ to odstΩpstwa zwi▒zane g│≤wnie z tym, ┐e pola logiczne w rekordzie, kt≤rych zawarto╢µ mo┐e przybieraµ tylko kilka warto╢ci, s▒ zdefiniowane jako tylko JEDEN ZNAK ASCII w rekordzie, - a nie przez PAR╩ znak≤w.
WiΩksze firmy produkuj▒ce pamiΩci EPROM, PROM lub mikroprocesory, wypracowa│y swoje w│asne modele dla omawianych zbior≤w. Wsp≤ln▒ cech▒ jednak jest kodowanie dla pojedynczego bajtu. Warto╢µ numeryczna bajtu jest reprezentowana przez dwa znaki ASCII. Pierwszy znak niesie soba warto╢µ dla starszej "czw≤rki" bit≤w, a drugi znak dla m│odszej "czw≤rki". W rekordzie zbioru wystΩpuje adres startu porcji. Adres taki mo┐e sk│adaµ siΩ z 2,3 lub 4 a nawet do 8 bajt≤w . Dla takich parametr≤w, jest te┐ zazwyczaj przyjΩta zasada, ┐e kolejne bajty jako PARY znak≤w ASCII odpowiadaj▒ kolejnym bajtom rejestru adresowego w kolejno╢ci HIGH ... LOW. Regu│a ta nie ma zastosowania dla zakodowanej tre╢ci PORCJI. Je┐eli jednostk▒ adresowania pamiΩci jest BAJT to problem interpretacji nie istnieje. Pojawia siΩ problem, gdy jednostk▒ adresowania jest s│owo 2-bajtowe WORD lub sk│adaj▒ce siΩ z wiΩkszej ilo╢ci bajt≤w. W≤wczas ustalenie kolejno╢ci HIGH...LOW lub LOW...HIGH jest konieczne.
Linki na temat:
Autor: Emmix.