For faster and more efficient programs, focus on performance engineering
What can you do about it? There are a number of practical steps that you can take to accelerate your code's run-time execution. We call these steps performance engineering. Performance engineering is a way to identify and reduce or eliminate performance problems during the software development cycle and after code has been designed and developed. It helps you make the correct cost/benefit trade-offs and attack performance concerns before they become issues. Rather than leaving performance problems until the end of development, you can build speed into your software from the very start!
The first two sections give you a general sense of what causes performance problems and basic strategies for eliminating them. The following sections provide a framework for effectively and consistently approaching performance improvement. It presents tools and concepts to help you improve your application's performance. It gives you a way to recognize and to control the cost of this activity and simultaneously obtain maximum benefits possible.
Bottlenecks have four major causes.
Another common source of useless computations are those made automatically or "by default", even if they are not required. Applications that needlessly free data structures during the shutdown of a program or open connections to workstations even though there isn't a user for them are examples of this type of bottleneck.
Needless re-computation: Programs sometimes re-compute values rather than storing (caching) them for later use. Bottlenecks are caused simply by wasting time re-computing the values. An example of a potentially needless re-computation is the determination of the length of a string. If this computation is embedded in a loop, the length of the string can be re-computed hundreds or thousands of times, each time resulting in the exact same value!
There are times, of course, when you must continually re-compute values because the cost (in terms of memory) of caching a value exceeds the cost of re-computation. Determining the costs and benefits of each will be discussed in a later section.
Excessive requests for services: Programs can make unnecessary requests for services, slowing down execution time and leading to bottlenecks. Excessive requests for operating system services are particularly expensive because, in addition to the time required to perform the service itself, the operating system must "context switch" simply to make the request and retrieve the result. This context switch operation incurs a larger overhead than a normal function call.
Waiting for service requests to complete: When programs request services, they typically "block." Blocking prohibits your program from continuing until the request is completed. Waiting for service requests to complete is a common bottleneck source. One of the most widely recognized bottlenecks of this type is synchronous communication (round-trip requests) between X-based applications and the X display server.
Waiting for service requests to complete can occur in a number of other important areas. One such area is retrieving data from a file on disk. Your program can incur a relatively lengthy stall even when accessing a local disk. If the file is mounted on a remote file system, however, the retrieval time via NFS can dramatically increase and be magnified by network delays.
Another area where delay can occur is when the program requests a page of main memory and that page is not present in the memory cache. The operating system must be called to retrieve the page from the swap device and load it into main memory. This, in turn might cause other pages to be written to the swap device to make room for the new page. Note that unlike the explicit file data retrieval requests mentioned above, these time consuming paging operations are triggered by an implicit request for data from memory. They are often caused by seemingly simple actions, such as de-referencing a pointer.
Bottlenecks occur whenever a computation or request is performed needlessly or inefficiently. These four categories represent most performance problems found in software programs.
There are five ways to attack performance bottlenecks.
Do Fewer calls for services. By making fewer calls you reduce the number of context switches that can dramatically slow down your program. Instead of requesting files that don't exist, double check the status of the requested file first, and then request only those.
By delaying computations or requests until they are needed or solicited, you can Do It Later. If your program can wait and make the calls for service during what would otherwise be user idle time, then the performance penalty of the context switch and service delay can be effectively hidden from the user.
Do It, But Don't Do It Again and cache a result, if possible, for later reuse. For example, X client's widgets often cache data available via a round-trip request to the X server. Changing your requests to use the cached data can save this expensive round trip request time.
You can solve bottlenecks caused by needlessly re-computing a string's length this way as well. Computing the value once, outside of the loop, storing it as a variable, and then using the stored length when needed will dramatically improve the performance of your program.
Finally, Do It Cheaper. Use an alternative algorithm that is less costly. For example, using a bubble sort when sorting a set of elements requires time proportional to the square of the number of elements in the set. On the other hand, using a quicksort requires time proportional to the number of elements multiplied by the log of the number of elements. Consequently, it is cheaper to use a quicksort routine for a large number of elements.
These five approaches can serve as a guide as you attack bottlenecks in your code.
We call this approach performance engineering. Performance engineering is a practical way to identify and eliminate bottlenecks.
Performance engineering is a process for consistently and effectively identifying and eliminating bottlenecks.

Figure 1. The Performance Engineering Process
As you can see in Figure 1, the performance engineering process starts by gaining an understanding of a program's execution and anticipating its bottlenecks. Once you've identified these potential bottlenecks, you must set objectives for eliminating them. After bottlenecks have been identified and improvement objectives set, several cycles of focused performance improvement follow. Each cycle is iterative, continuing until the performance objective is met or the cost of meeting the objective exceeds the expected benefit.
Review the phases your program is designed to execute.Consider a typical X-Window application. The common flow of an X client program is to initialize internal data structures, register callback functions, open a connection to the user's display, then send the initial window layout to the X server. Once this initialization phase is complete, the program enters an event wait loop. When the user clicks on a button or makes a menu selection, the appropriate function in the X client is invoked, usually affecting both internal data structures and external X windows. The program continues in the main event loop until the user requests an exit. This final phase ensures that all files are saved, then exits the X windows system.
Determine which phases are most time-consuming.Given this design, we can identify an initialization phase, phases for each user-invoked function (in X parlance, these are known as 'callbacks'), and a final exit or shutdown phase. Each phase allows you to anticipate which types of bottlenecks might be present.
For instance, during initialization a lot of computation is done to set up data structures and user interface support. These computations can range across vast data spaces, causing startup paging effects as the program requires more memory to hold the data. Also, in order to build these data structures, the program often retrieves data from files, making explicit (and potentially time consuming) requests of the operating system.
After the program enters the main event loop, its computation is largely driven by user requests. Nevertheless, you can review the types of computations that will occur within the callbacks and anticipate which callbacks, or sequence of callbacks, are likely to prove performance bottlenecks. Some will be due to expensive X requests (including the use of round-trip X server requests for data), while others result from updating the internal state of the program.
Understanding how program performance scales with changes in data size will help you estimate the magnitude of bottlenecks.The key observation, however, is that the callback structure provides a natural way to anticipate, and later verify, the bottlenecks in the program. Whether or not you're programming in X, though, as a developer you probably have a good idea of which phases will tend to be the most time consuming and what types of bottlenecks might be present.
Once you've identified the phases of your program, you should then try to anticipate how the performance of each phase will change as the data "scales up". Algorithms that perform acceptably when the amount of data they process is small will often become inefficient as the volume of data increases. If you're sorting a small set of numbers, a bubble sort can be a fine choice; beyond a dozen elements or so, however, its performance breaks down and a better algorithm is needed. Understanding how program performance scales with changes in data size will help you estimate the magnitude of bottlenecks. It will also help you avoid unexpected performance problems, problems that have an unfortunate habit of turning up at customer sites.
Build a rough timeline of the program's execution, including anticipated bottlenecks, and set a performance baseline.A review of your program's phases will enable you to build a rough timeline of the program's execution, including anticipated bottlenecks. Any scaling effects would be reflected as expected increases in processing time for different phases. Once the timeline is constructed, you should use a performance analysis tool (see page 15 for what tools are right for you) to perform a quick examination to confirm your estimates and ferret out any surprises. This analysis doesn't have to be tremendously accurate since the estimates themselves are only approximations at this point. Besides setting a performance baseline for comparison with future improvements, this rough analysis will also suggest (or confirm) critical areas where you will want to focus your attention in the next step.
The benefit of fixing any bottleneck is weighed against the cost (in time and frustration) of identifying and fixing it.After identifying possible bottlenecks, you will need to prioritize them. There are several criteria for this, the most obvious being the magnitude of performance improvement you can expect if you can identify the cause of the bottleneck and fix it. It's really a cost versus benefit analysis--where the benefit of fixing any bottleneck is weighed against the cost (in time and frustration) of identifying and fixing lt.
An important aspect of finding the cause of a bottleneck is the efficiency and accuracy of the analysis tools. If, for example, the tool requires recompilation or re-coding to acquire accurate data, you will incur a high cost when you make the modifications, perform the recompilation (which may require additional disk space for a separate build), and then account for any discrepancies due to either compilation option changes or the overhead of the tool itself. These inefficient and intrusive deviations from the normal build and test cycle add to the cost of isolating the bottleneck and can become a major obstacle to further performance engineering.
Focus on both the interfaces and the code you control.Furthermore, finding the exact cause of a bottleneck requires tools that can gather accurate performance data. For example, fixing most bottlenecks requires an understanding of calling sequences -- you might be able to avoid making many of the calls -- and an understanding of which source lines contributed to the computationally intense activity. Achieving this accuracy and specificity carries a cost of data collection overhead, but is repaid in reduced analysis time. Because the performance data pinpoints the problem, you spend less time guessing and more time fixing.
Indeed, the time spent analyzing and understanding the performance data will dominate most performance engineering projects. Tools that present data in easy-to-read formats or data that reflects the actual performance of the program will reduce your analysis time and help you focus on the right bottlenecks to fix.
You also need to estimate the cost of reducing or eliminating the bottleneck once identified. One obvious criterion is that you should have control over the software containing the problem code. Usually this means having control over the source and the algorithms computing various results. Just as importantly, however, it also means having control over the code that requests various services, especially operating system services.
While it is true that you can't rewrite code providing a set of services in a third-party or system library, you can control the frequency and arguments of your calls to those services. If you can change calling sequences or find alternative functions that are faster, you can make considerable progress on bottlenecks in these areas.
Using these criteria, you can estimate the expected cost and benefit of fixing different bottlenecks. The estimates can be rough: the point is to evaluate all your options so you can make an informed choice about which bottlenecks offer the highest benefit-to-cost payback.
The goal of each improvement cycle is to isolate and eliminate a particular bottleneck.
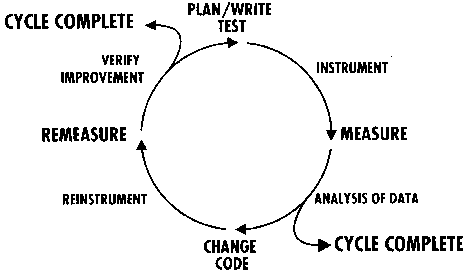
Figure 2. The Performance Improvement Cycle
The goal of each improvement cycle is to isolate and eliminate a particular bottleneck. It consists of making a series of specific measurements, analyzing that data, implementing a code change, and then verifying that the change led to a measured improvement. This cycle of verified performance improvement continues until the expected cost of the next step in the cycle outweighs the expected performance gain. At this point, another bottleneck is chosen.
Having chosen a specific bottleneck, you should select test cases that demonstrate the bottleneck under difference conditions. The scaling effects discussed earlier should be considered at this time. Tests should also help analyze the impact of different environments, including system and network load.
Instrumentation is the next phase of the cycle. Select points in your code that will maximize your knowledge of performance. Be sure to choose the proper sample interval to ensure that the bottleneck will be revealed. In particular, you should make the sample interval comprehensive enough so if several small delays are combining to form a bottleneck, you will see the effect. This type of delay is often found in code that, for instance, interleaves file access and computation.
It is important to verify the improvement over all the test cases you assembled and over different operating conditions.Next, collect your measurements. It might take several runs to collect accurate data because of variations in network and processor load.
Your analysis of the collected data should attempt to isolate the cause of the bottleneck. Using the four categories of bottlenecks discussed above, identify the specific code sequences that perform useless and needless computations or that make excessive service requests or requests that stall. Once isolated, you can then choose how to improve the situation. Consider the approaches also outlined above: delaying or avoiding a computation altogether, making fewer requests, caching results, etc.
You might find that the correct improvement requires a significant design change, which would incur a substantial cost. You may decide, at this point, to suspend work on this bottleneck and move on to another, unrelated bottleneck.
If you decide to make a change to improve the code's performance, you need to re-instrument and re-measure the changed code. Make sure that the original sample points and instrumentation are still applicable to the changed code.
Once the new data is collected, you should compare it with the previous data and verify that the expected improvement has been made. It is important to verify the improvement over all the test cases you assembled and over different operating conditions. This will ensure that you have not introduced new bottlenecks unknowingly that may appear only under certain conditions.
If the code change results in an acceptable improvement to performance, you can use the most recent performance data as a new baseline for the next cycle of improvement on this bottleneck. Analyzing this data may suggest additional improvements, which would then add another cycle of making and verifying the improvements. The cycle stops whenever the expected cost of making and verifying an improvement outweighs the expected performance gain. At this point, it is time to move on to the next bottleneck.
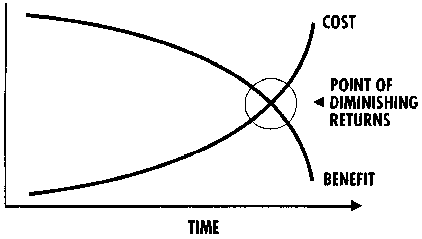
Whenever you are evaluating whether to proceed with another step in a performance improvement cycle, you should determine whether it might be better to move to the next bottleneck given its expected gain and cost. This allows you to evaluate the diminishing return of improvements on one bottleneck versus another.
Figure 3. Diminishing returns
One final aspect of evaluating the cost and benefit of each improvement involves understanding the lost opportunity cost of not attending to other development tasks. After all, there is often little to be gained by prematurely optimizing one particular phase of a program if the rest have not been developed or tested. Performance engineering is an integral part of all of software engineering and, as such, its goals must be considered in light of the combined engineering goals of software development.
This is a key element of performance engineering: Make bottlenecks easy to identify and then easy to verify when eliminated.Too often, performance improvement is attempted after the code is written and tested. At this point it is difficult to make changes to the code that will dramatically improve performance and that can be tested adequately before the product ships.
By uniformly practicing performance engineering throughout development and testing you will ship much faster code. While most engineers have a good sense of the expected performance during design, they rarely design the code to make verification of those expectations easy. This is a key element of performance engineering: Make bottlenecks easy to identify and then easy to verify when eliminated. This involves anticipating different possible scaling effects and test cases, designing the sampling points, and having the right tools to gather rough timing data early to reduce the number of surprise bottlenecks found later.
Collecting timing data early in development benefits your future development of code as well as reinforces the need to choose design alternatives that will aid in later performance improvement. But focused improvement, as carried out in performance improvement cycles outlined above, need not happen until later in the project, after good test cases are available and the majority of functions are available to test. At this point you will be able to make more informed trade-off decisions about which bottlenecks to focus on and which improvements to make.
The tools you use are critical for successful performance improvement.Effective performance engineering relies on performance analysis tools that provide accurate data, that are easy to understand, and that are easy to focus. Such tools reinforce performance engineering as a discipline and permit a consistent approach to performance improvement. It is this consistent practice that leads to the highest performance software in a marketplace.
What criteria should you use when evaluating tools to assist in your performance engineering effort? The following is a list of important factors to consider:
Slow performance is a defect in your code. To eliminate this defect, you need to attack performance bottlenecks consistently and effectively. Performance engineering -- grounded in practical cost/benefit trade-offs -- gives you a way to do it. Performance engineering gives you a practical approach to faster code.
![[More Information?]](/file/16967/CDware_Sep-Dec_1995.bin/.products/Pure/moreinfo.gif)