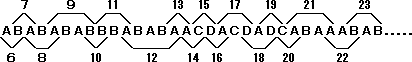
| ■ 補足資料 -画像の圧縮形式について- |
画像を保存しようとしたとき、その保存形式に迷うことは少なくないと思います。それぞれのフォーマットがどのような圧縮技術を用いているのか、そしてその長所、短所を知っていれば、判断を下しやすくなります。ここでは画像の保存形式としてメジャーなGIF形式とJPEG形式について、そのアルゴリズムをできるだけ分かりやすく説明しようと思います。
自分はプログラマでもなんでもないので、間違いや不正確な部分があるかもしれません(^^;。ここでの記述は参考程度にお考えください。また、もしそうした個所を見つけましたら、ぜひご教示ください。
GIF形式は「Graphics Interchange Format」の略で、アメリカのパソコン通信ネットワーク「CompuServe」で提唱されたフォーマットです。65535×65535ドット、256色までの画像を扱うことができます。現在、GIFにはGIF87、GIF87a、GIF89aという3つのバージョンがあります。GIF87は通常の静止画像のみを、GIF87aは静止画像とインタレース表示(インタレースGIF)をサポートしています。GIF89aはこれに加えて透明色指定(透化GIF)とアニメーション(GIFアニメーション)を可能にしたものです。
このフォーマットではデータの圧縮に「LZW(Lempel-Ziv Welch)圧縮法」という技術を使っています。これはごく大雑把に言えば、ある決まったデータ列に名前を割り当て、その名前だけを保存しようという方法です。
例えば「YYYYY」というデータを保存するときに、「YYYYY」とそのまま保存するより「Y5」という風に表したほうがデータ量が小さくて済みます。この方法を「ランレングス(Run length)圧縮法」といいますが、「LZW圧縮法」はこれをさらに巧妙に発展させたものです。
cf.
「LZW圧縮法」はアメリカのUnisys社が特許を持っています。詳しくは「GIFの特許問題」をご参照下さい
今、簡単のためにA,B,C,Dという4色からなる、以下のようなデータを考えます。
ABABABABBBABABAACDACDADCABAAABAB.....
このデータを頭から順に見てゆき、新しい順列が現れるたび、新しいコードをその順列に割り当てていくのです。ただし例外として、この場合0~5番までのコードは予約されます。0~3まではA,B,C,Dそれぞれの色が割り当てられます。また、4番はクリアコード、5番はエンドコードという特別のコードとなります。そこで、データの表記は6番以降のコードを用いて行います。
さて、始める前に新しい言葉を導入します。「ABCD」というデータ列があった場合、最後のデータを除いた部分を「プレフィックスストリング(prefix string)」、最後のデータを「サフィックス(suffix)」と呼びます。この場合、プレフィックスストリングは「ABC」、サフィックスは「D」ということになります。
この「プレフィックスストリング」とか「サフィックス」という呼び方は、多分正式なものではありません(分からないけど)。でもこう呼ぶと分かりやすいので、ここでは便宜的にこれらの用語を使います。
以上のことを頭においておいて、実際にやってみましょう。頭から見ていくと、最初に「AB」というデータの並びがあります。これに6番のコードを割り当てます。そして、このデータ列のプレフィックスストリングを記録します。この場合、プレフィックスストリングは「A」、すなわちコード「0」です。
そうしたら次は、今処理したデータ列(「AB」)のサフィックス(「B」)から読み始めます。すると「BA」というデータ列が出てきました。これに7番のコードを割り当てます。そしてこのデータ列のプレフィックスストリング「B」、すなわちコード「1」を記録します。
どんどん進めていきましょう。続くデータを読んでいきます。「ABA」という並びが出てきました。8番のコードを割り当てます。そしてこのデータ列のプレフィックスストリング「AB」、すなわちコード「6」を記録します。以下同様にして、コードをデータ列に割り当て、プレフィックスストリングを記録していきます。
これを続けていくと、最終的に下の表のようになります。
| 色 | コード | プレフィックス | サフィックス | データ列 | 出力 |
|---|---|---|---|---|---|
| A | 0 | ||||
| B | 1 | ||||
| C | 2 | ||||
| D | 3 | ||||
| Clear | 4 | ||||
| End | 5 | ||||
| A | A | A | - | ||
| B | 6 | A | B | AB | 0 |
| A | 7 | B | A | BA | 1 |
| B | |||||
| A | 8 | 6 | A | ABA | 6 |
| B | |||||
| A | |||||
| B | 9 | 8 | B | ABAB | 8 |
| B | 10 | B | B | BB | 1 |
| B | |||||
| A | 11 | 10 | A | BBA | 10 |
| B | |||||
| A | |||||
| B | |||||
| A | 12 | 9 | A | ABABA | 9 |
| A | 13 | A | A | AA | 0 |
| C | 14 | A | C | AC | 0 |
| D | 15 | C | D | CD | 2 |
| A | 16 | D | A | DA | 3 |
| C | |||||
| D | 17 | 14 | D | ACD | 14 |
| A | |||||
| D | 18 | 16 | D | DAD | 16 |
| C | 19 | D | C | DC | 3 |
| A | 20 | C | A | CA | 2 |
| B | |||||
| A | |||||
| A | 21 | 8 | A | ABAA | 8 |
| A | |||||
| B | 22 | 13 | B | AAB | 13 |
| A | |||||
| B | 23 | 7 | B | BAB | 7 |
以上の操作によって、
ABABABABBBABABAACDACDADCABAAABAB.....
というデータ列は
0168110900231416428137.....
というコード列に変換されます(分かりにくかったら、実際に紙と鉛筆使ってやってみてください。雰囲気がつかめると思います)。
データ列の長さとコード列の長さを比べてみてください。短くなっています・・・ということは、データが圧縮されたということです。以上のような圧縮方式を考えれば、どのような画像がGIFに向いているのかはおのずと明らかです。
GIFは、アニメの絵のように1つの色の面積が広かったり、規則的な図形が繰り返されるような絵で最大の圧縮効果を発揮します。
逆に、違う色のドットが不規則に並んでいたりするような画像では、圧縮の効果が下がりファイルサイズが大きくなりがちです。また、写真などでは256色という色数の制限から、きれいに再現するのはなかなか難しいです。さらにこうした画像では256色以内に色数を押さえるために「減色」をしますが、このとききれいに再現しようとして誤差拡散法などを使うと、上記の理由でファイルサイズが大きくなってしまいます。
さて、ここからはオマケですが、圧縮したままじゃ気持ち悪いという方もおられるかと思うので、次は圧縮されたデータを展開してみましょう。
展開の仕方は一見難しそうですが、実はそれほどでもありません。展開するためには上に示したようなコードとデータ列との対照表を、コード列から復元する必要があります。0~5番までのコードは割当があらかじめ決まっていますから、復元する必要があるのは6番以降です。
0168110900231416428137.....
まず、コード列の頭から順番にコードのペアを作っていきます。そして、できてきたペアのそれぞれから、6番以降のコードを順次求めることができます。今回の場合、最初のペアは(01)です。すると、こうして作ったペアの左側のコードが6番のコードのプレフィックスストリングを、右側のコードの最初の1文字が6番のコードのサフィックスを表します。
と、言葉で説明しても分かりにくいでしょうから、実際にやってみましょう。
まず最初のペアは上記のように(01)です。ですから、6番のコードのプレフィックスストリングは「A」、サフィックスは「B」となります。つまり、6番のコードは「AB」を表します。
次のペアは(16)です。ここから、7番のコードのプレフィックスストリングは「B」。そしてサフィックスは「コード6番=AB」の最初の1文字、 「A」です。つまり、7番のコードは「BA」を表します。
3番目のペアは(68)です。よって8番のコードのプレフィックスストリングは「コード6番」すなわち「AB」です。そしてサフィックスは・・・といきたいところですが、これを埋めるためには今求めようとしているコード8番のプレフィックスストリングが必要です。おっと、8番のコードのプレフィックスストリングはたった今、求めたばかりでしたね。そう、「AB」です。ですから、コード8番のサフィックスは「AB]の最初の1文字「A」となり、コード8番は「ABA」というデータ列を表すことが分かります。
後はもうこれを繰り返していくだけです。4番目のペアは(81)ですから、コード9番のプレフィックスストリングは「コード8番=ABA 」、サフィックスはBです。すなわち、コード9番は「ABAB」を表すということになります。
これを続けていけば、すべてのコードについてデータ列を割り当てることができ、データを復元することができます。