Princip rozpoznávání textu
Mnoho uživatelů již řadu let používá programy pro rozpoznávání obrazů (OCR) ke zpětné transformaci textových informací a k jejich následnému zpracování. Většina z nás ale nemá představu, jakým způsobem tyto programy fungují.
Vědecké výzkumy v oblasti počítačového vidění postupují poměrně pomalu. Donedávna byl základním prvkem v těchto systémech fotočlánek, který mohl měřit jas v jednom bodu. O kvalitativní úrovni těchto systémů nemá smysl hovořit. Mohou pouze určovat přítomnost nebo absenci nějakého objektu nebo určit jeho přibližné rozměry. Ale s vývojem digitální techniky se objevily skenery a digitální kamery. Základem jejich konstrukce je čip s několika miliony CCD prvků citlivých na světlo. Nová technika značně rozšířila možnosti těchto senzorů, které dodávají informace z okolního prostředí pro další zpracování a analýzu. Nicméně bez ohledu na neustálé vylepšování techniky a algoritmů jsou pro plnohodnotné rozpoznávání obrazů nutné výpočetní kapacity zcela jiného řádu.
Vznikl zde také nový problém, spojený s nedostatkem poznatků o tom, jak se zpracovává vizuální informace v lidském mozku poté, co světlo zaostřené oční čočkou dopadne na tyčinky a čípky sítnice našeho oka.
Existuje ještě jedna důležitá zvláštnost v lidském vidění. Na rozdíl od počítače můžeme jeden a ten samý objekt vnímat různě: buď odděleně, nebo jako část jiného objektu nebo celku - v závislosti na okolí. Problém vyhledávání a vyčlenění jednoho objektu dnes nemůže být vyřešen v současných OCR algoritmech kvůli složitosti zrakového vnímání člověka.
Obvykle se dokumenty pro následné rozpoznávání skenují v 256 odstínech šedi. Pro efektivní rozpoznávání ale potřebuje mít OCR algoritmus dokument v dvoubarevném formátu, aby mohl rychle a jednoduše rozeznat a odlišit barvu pozadí a barvu textu nebo linie. Samozřejmě že se dá skenovat dokument okamžitě v dvoubarevném formátu a soubory jsou tak osmkrát menší. Ale protože algoritmy skenerů transformují zobrazení do dvoubarevného formátu hůře než algoritmy, které se používají v OCR programech, je přece jen lepší skenovat v 256 odstínech šedi.
Rozpoznávání formulářů - tiskopisyJedná se o formuláře, které se obvykle tisknou v tiskárnách a mají standardní rozměry, ale políčka se v nich zaplňují psacím strojem nebo ručně. Perspektiva neustálého rozpoznávání standardního formuláře a vyhledávání nepotřebných bloků nikoho nepřitahuje, proto se v takových případech obvykle rozpoznávají jednotlivá textová pole a potom se výsledek ukládá ve formě tabulky nebo databáze. V jednodušším případě, kdy jsou tiskopisy v dostatečně dobré kvalitě pro OCR algoritmus, stačí ukázat všechna pole nutná k rozpoznání obsahu ve tvaru obdélníkových oblastí. Pro reálné úkoly to však není dostačující. Na standardních formulářích chybí jakákoliv informace o základních bodech dokumentu (souřadnice bodů, od kterých začíná odpočet polí dokumentu). Vzniká vážný problém spojený s tím, že automatický skener ne zcela přesně uchopí dokument, následně ho nepředvídatelně vertikálně nebo horizontálně posune, nebo se dokument dokonce nepatrně pootočí o malý úhel. Kvůli tomu v místě, kde OCR algoritmus očekával textovou informaci, obdrží buď prázdný kus dokumentu, nebo jen část potřebného pole, a všechna práce OCR algoritmu tak ztrácí smysl. Pro vyřešení tohoto problému je nutné použít speciální opravný algoritmus, který dokáže na základě obsahu dokumentu získat potřebnou informaci o posunu a pootočení dokumentu pro jeho další správné rozpoznání. Složitější je řešení problému s pootočením, protože pro pootočení dokumentu o libovolný úhel se používají operace s pohyblivou řádovou čárkou. Úhlová korekce zabírá velmi mnoho času, dokonce více než rozpoznávání polí. Kvůli algoritmické složitosti této korekce se prakticky nikde nerealizuje. Ani pro člověka to není jednoduchý úkol, nehledě na to, že náš mozek bez zvláštní námahy neustále vykonává velké množství obdobných operací. Kromě toho vzniká problém spojený s tím, že vizuálně podobné tiskopisy byly tištěny v různou dobu a v různých tiskárnách, a proto mohou mít souřadnice polí nepatrně rozdílné rozměry, což způsobí posun jedněch polí vzhledem k jiným. V těchto případech je pro rozpoznávání dokumentu jednoho tiskopisu s menšími odchylkami obvykle nutné používat několik podobných šablon. |
V nejjednodušším případě je možné pro transformaci do dvoubarevného formátu zadat konstantní úroveň prahu jasu pro rozdělení bodů. Ale kvůli různým parametrům jasu a kontrastu předloh bude takový algoritmus informaci zkreslovat vždy, když se jas dokumentu bude lišit od standardního.
Jestliže začneme dokument postupně zesvětlovat (zvyšovat jas), bude se postupně zmenšovat tloušťka linií znaků, dokud nezmizí jednotlivé části znaků a celý znak se neslije se světlým pozadím. Při zvýšení jasu může stále menší množství bodů překonat mez světlosti. A pokud budeme naopak dokument zatemňovat (snižovat jas), linie znaků se budou postupně rozšiřovat, dokud se nezačnou spojovat se sousedními a potom zčerná celé pozadí. Taková zkreslení znemožňují rozpoznávání jednotlivých znaků. Ještě je možné udělat pohyblivou hranici mezi černou a bílou. Například určit průměrný odstín a podle něj spočítat rozdílovou mez nebo najít bod s minimálním a maximálním jasem a hranici spočítat jako jejich průměr.
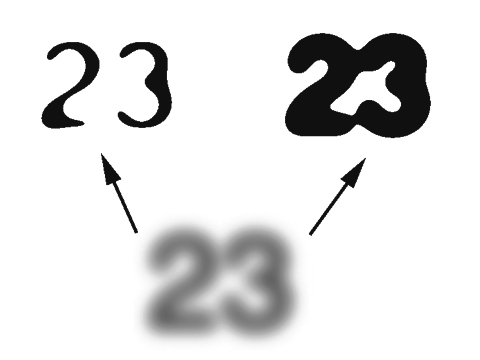
Tyto algoritmy budou úspěšnější, ale vznikne jiný problém, spojený s nerovnoměrným osvětlením dokumentu. Například levá strana je osvětlená a pravá je zatemněná a mezi nimi je plynulý přechod. Předchozí algoritmus zjistí mez podle celého dokumentu, provede transformaci a vznikne následující situace: znaky uprostřed dokumentu budou dobře viditelné, ale znaky zleva budou často porušené, znaky zprava budou zalité černě. Tento problém je neřešitelný pomocí univerzálních programů. K tomu je zapotřebí intelektuálnější algoritmus, který bude analyzovat dokument po částech, zjišťovat mez a transformovat ho do černobílého formátu.
Úkol transformování dokumentu z formátu 256 odstínů šedi do dvoubarevného není v praxi až tak jednoduchý. Je nutné použít specializované algoritmy, potřebné pro kvalitní zpracování dokumentů s rozdílným rozložením jasu. Tento problém je aktuální především pro dokumenty napsané na psacím stroji přes kopírovací papír. Vzhledem ke zvláštnosti tisku je barva uvnitř obrysu znaku temnější než zvenčí a po přetransformování do černobílého formátu se jednotlivé linie znaků slévají, což způsobuje chyby.
Po získání dvoubarevného zobrazení v dostatečné kvalitě mohou na obrazu zůstat jednotlivé náhodné body nebo menší skupiny bodů, které vnáší chyby do procesu rozeznávání. Zpracováním základních parametrů skupin, jako je například hustota skupiny, rozměr prvku a vzdálenosti mezi jednotlivými sousedními prvky, je možné vybudovat filtr pro odstranění nejrůznějších šumů.
Nejčastěji se objevuje vysokofrekvenční šum, projevující se body rozházenými na pozadí. K jeho odstranění je zapotřebí provést analýzu sousedních bodů, a pokud je plocha jednotlivého kousku mnohokrát menší než plocha znaku, je možné ho odstranit. Složitěji se provádí odstranění "smetí" středního rozměru, vždyť jeho velikost může být srovnatelná s rozměry jednotlivých částí písma. Stává se, že jsou to náhodné kousky linek nebo črtů.
V souvislosti s tím, že dokumenty nejsou vždy ideální, mohou být písmena rozdělena trhlinami. V tomto případě může vést pokus o zvětšení rozměru odstraňovaného středněfrekvenčního šumu k odstranění významných částí znaků a k následné nemožnosti jejich rozpoznání. Proto je možné odstraňovat středněfrekvenční šum jen v případě, když je stabilní, dobře rozeznatelný a nekryje se s možností porušení znaku.
Perceptron
Pro rozpoznávání jednotlivého znaku je možné použít různé algoritmy. Jedním
z prvních byl algoritmus s názvem Perceptron. Velmi dobře se uvedl a ve své
době znamenal převrat v teorii rozpoznávání obrazců. Pro rozpoznání se používá
matrice senzorů, kde každý senzor odpovídá za stav skupiny bodů v určité oblasti.
Výstupem senzoru je buď stav pozadí, nebo stav barvy jako části znaku. Podle
toho, které senzory se nacházejí ve stavu Pozadí a které ve stavu Znak, je možné
poměrně přesně určit, který znak se nachází na vstupu Perceptronu, případně
dojít k závěru, že jde o neznámý znak.
Maximální automatizaceSpeciální formuláře pro OCR programy |
Tento algoritmus se v nejjednodušším případě používal v některých zemích na poštách při čtení poštovních směrovacích čísel. V tomto případě byly velmi dobře známy souřadnice každého znaku a také jeho hranice. Nejsou zde problémy se znaky různých velikostí, měřítko je také známé, nemělo by vznikat ani různé naklonění znaků. V tomto případě je použití algoritmu Perceptron ideální.
 Měřítkový
Perceptron
Měřítkový
Perceptron
Pokud zkusíme použít Perceptron (určený pro zpracování fixního písma) pro rozpoznání
běžného tištěného textu, pak asi sotva obdržíme obstojný výsledek. V dokumentu
mohou mít znaky různé rozměry v pixelech, dokonce i když mají shodné rozměry
v milimetrech, protože dokument můžeme skenovat s různým rozlišením. Tato skutečnost
brání v použití "standardního" Perceptronu. Ale protože předchozí
algoritmus ve své oblasti pracoval efektivně a nic lepšího nebylo k dispozici,
byl nepatrně vylepšen a na světě se objevil měřítkový Perceptron.
Základní rozdíl mezi ním a jeho předchůdcem je v tom, že se přepočítávají horizontální a vertikální měřítkové koeficienty podle rozměru znaku. To znamená, že pokud je znak x-krát větší než etalon, zvětšíme na tento rozměr síť senzorů, pokud je znak menší, příslušně síť senzorů stlačíme. Ve finále získáme síť senzorů, která se jakoby natahuje na znak nezávisle na jeho rozměrech a každý senzor se nachází v ekvivalentním bodě znaku. Takový algoritmus již bude poměrně spolehlivě fungovat při rozpoznávání textových dokumentů.
Neuronová síť
Další vývoj tohoto algoritmu pokračoval v pokusech o rozpoznávání rukopisného
textu. Obyčejný rukopisný text se zatím nedaří přečíst, vážné problémy vznikají
dokonce při pokusu o rozdělení slova na znaky. Například písmena "u"
a "i", napsaná souvisle v jednom slově, může program interpretovat
jak jako "ui", tak i jako "iu". Proto se vývojáři vydali
cestou zjednodušení algoritmu, byly vytvořeny speciální formuláře, ve kterých
se každý jednotlivý znak psal do jednoho políčka standardního rozměru. Pak odpadl
problém rozdělení znaků, ale zůstal problém rozpoznání znaku. Měřítkový Perceptron,
který se tak dobře hodil pro rozpoznávání tištěných znaků pevným souborem písem,
se zde ukázal jako bezmocný. Základní problém spočívá v tom, že dříve jsme rozpoznávali
tištěné texty, kdy se jeden a tentýž znak prakticky úplně shodoval se všemi
obdobnými znaky nanesenými jeden za druhým, a mohli jsme rozmístnit senzory
v různých oblastech znaku. Při nastavení takové sítě se senzory objevují vždy
přesně na stejném místě znaku a můžeme posuzovat shodu znaků podle počtu shodujících
se signálů od senzorů.
S ručně psanými znaky je vše úplně jinak. Jejich linie nejsou ideální, mohou se lehce posouvat, tím se odklánět od senzoru odpovídajícího za danou oblast a dostat se k senzoru sousednímu. Vždy vzniká problém s nepřesností, když může linie částečně procházet přes senzor a on může se stejnou pravděpodobností vydat signál Pozadí nebo Znak v dané oblasti. Tyto problémy se částečně podařilo vyřešit použitím neuronových sítí v roli senzorů. Ty mohou vydávat na výstupu nikoliv pouze binární signál, ale míru pravděpodobnosti, která zachycuje přítomnost části znaku v dané oblasti. Koeficient, kterým se násobí signál po vstupu na senzor neuronové sítě, je možné měnit a tímto způsobem přizpůsobovat síť k rozpoznávání znaků, které se lehce liší jeden od druhého. Použitím neuronové sítě se podařilo naučit program rozeznávat tiskací znaky psané rukou.
Typy dokumentůUniverzální dokument s blokovou strukturou OCR algoritmus může analyzovat obraz, který se vztahuje k jednomu znaku, proto je předem potřeba rozdělit textový blok na řádky, řádky na slova a slova na jednotlivé znaky. V souvislosti s tím, že se znaky uprostřed slova mohou často vzájemně slepit, je lepší použít různé algoritmy pro rozdělení slov a pro rozdělení znaků ve slově. Potom již máme všechny potřebné informace pro rozpoznávání jednotlivých znaků - jsou to souřadnice znaků a jejich hranice. |
Bez ohledu na určitý úspěch při použití neuronové sítě zůstaly i problémy. Při neustálém zvětšování množství znaků, na které byla síť naučena, se začíná její přesnost po dosažení určité hranice (okolo 98 % - podle kvality znaků) zmenšovat. Je to spojeno s nahromaděním chybných vzorů. Znaky, na kterých se síť učí, nejsou ideální, některé z nich nejsou napsány dostatečně správně. A program, když se učí na těchto chybně napsaných znacích, odbourává správné koeficienty a vytváří místo nich nové. Pokud budeme program poměrně dlouho učit, pak (v souvislosti s nahromaděním chybných symbolů v jeho znalostech) bude přesnost rozpoznávání klesat.
Všechny výše uvedené metody mají jeden společný nedostatek: pro další analýzu používají jako zdroj základní informace senzory. Tyto senzory jsou připoutány k určité fixní oblasti. Ale protože je senzorů mnohem méně než pixelů v dokumentu, získáme hrubší obraz o rozpoznávaném objektu. Tímto způsobem se snažíme zmenšit objem informací určených k dalšímu zpracování a zjednodušit algoritmus, ale to dělá vnímání obrazu hrubším, než je ve skutečnosti, a vede ke značnému zvýšení pravděpodobnosti vzniku chyby dokonce u těch obrazců, které se bez zvláštního úsilí vizuálně lehce identifikují okem člověka.
Vektorizace
Na vektorizaci můžeme pohlížet jako na určitou fázi při transformování znaků,
která poměrně přesně zachycuje jejich podstatu bez významné ztráty užitečné
informace. Po vektorizaci značně zmenšíme objem informací, který je potřebné
dále zpracovat. To zjednodušuje algoritmus a program může fungovat podstatně
rychleji. Kromě toho po vektorizaci můžeme vyřešit okamžitě několik velmi složitých
problémů, jako například určení měřítka objektu, jeho úhlové parametry (například
společný úhel naklonění znaků). Místo hledání znaku sítí senzorů po celém dokumentu
(což zabírá velmi mnoho času) můžeme najít všechny spojené skupiny vektorů.
Jakmile máme strukturovaný vektorový model obrazce, který hledáme, můžeme jej
poměrně přesně porovnat. Například pro číslici jedna bude vektorový popis asi
následující: první vektor svírá s druhým úhel blízký 45°, první vektor je přibližně
dvakrát větší než druhý. A pro číslici sedm: první vektor svírá s druhým úhel
blízký 90°, první vektor je přibližně dvakrát větší než druhý.
Parametrické metody
Obdobně jako vektorizace existují metody, které zobrazení sice analyzují, ale
předem ho nezjednodušují. Pokud si během vektorizace snažíme představit obraz
jako strukturu linek a obrysů, pak parametrické metody naopak vyhledávají jednotlivé
významné objekty. Jestliže určíme, že aktuální bod náleží k přímce, nedá nám
to žádnou informaci. Důležitější je vědět, kde se nachází začátek a konec linky.
Tyto významné objekty mohou být konce linky, přímky nebo křivky, ale také bod,
ve kterém linie ostře mění svůj směr, nebo bod - průsečík linií, nebo třeba
uzavřený obrys. V takovém mimořádně abstraktním popisu může vypadat nula jako
jeden uzavřený obrys, osmička jako dva spojené uzavřené obrysy. Takový popis
můžeme použít pro rozpoznávání textů natištěných různými druhy písma, napsaných
různými lidmi a bude vždy fungovat na sto procent, samozřejmě pokud budou znaky
zobrazeny bez podstatných chyb.
 Bez
ohledu na to, že existují poměrně přesné algoritmy pro rozpoznávání znaků, máme
programy, které umí spolehlivě rozpoznat pouze typografické dokumenty nebo texty
vytištěné na tiskárně. Zatím si nemůžeme dovolit zapisovat výsledky na papíru
a potom je rychle, bez zvláštního úsilí, zadat do počítače pro další zpracování.
Bez ohledu na pokusy, se kterými se setkáváme u současných PDA počítačů, pro
nás zatím zůstane klávesnice jediným rozhraním do digitálního světa. Vše proto,
že reálné obrazce, které vytváříme, se podstatně liší od těch laboratorních,
na kterých se testují OCR programy.
Bez
ohledu na to, že existují poměrně přesné algoritmy pro rozpoznávání znaků, máme
programy, které umí spolehlivě rozpoznat pouze typografické dokumenty nebo texty
vytištěné na tiskárně. Zatím si nemůžeme dovolit zapisovat výsledky na papíru
a potom je rychle, bez zvláštního úsilí, zadat do počítače pro další zpracování.
Bez ohledu na pokusy, se kterými se setkáváme u současných PDA počítačů, pro
nás zatím zůstane klávesnice jediným rozhraním do digitálního světa. Vše proto,
že reálné obrazce, které vytváříme, se podstatně liší od těch laboratorních,
na kterých se testují OCR programy.
Reálné obrazce, které vytváříme, obsahují velké množství šumu a je nemožné vzít v úvahu všechny varianty jeho potlačení. Náhodné skvrny, kaňky, tečky, rozpíjející se linie, náhodné čmárance, škrtance a opravy, překrývání jednotlivých obrazců, razítka a tisky a částečná ztráta informací na faxech; ohromné množství obrazců, různé jazyky, podmínečná označení, různé druhy písma - všechny tyto okolnosti dnes znemožňují univerzální řešení problému rozpoznávání textu. Pro řešení tohoto problému budou zapotřebí ještě výkonnější počítače a ohromné bloky paměti.
Grigorij Lukašenko
 |