Seznamy, unikáty, filtrování dat
|
Jak název napovídá, tento díl se bude věnovat seznamům. Pod pojmem seznamy si v tutu chvíli představte oblast dat tvořenou sadou záznamů v řádcích pod sebou. Máte-li například svou domácí hudební sbírku, pak záznamem je konkrétní album s položkami interpret, název alba, hudební žánr a rok vydání umístěnými v jednotlivých sloupcích. O dlouhém seznamu můžeme mluvit také jako o databázi.
|
|
Z osmdesáti procent seznamy dotváříme tak, že nové záznamy doplňujeme na konec seznamu. Pak často vyvstane potřeba data abecedně seřadit. K tomu postačí umístit kurzor do seznamu a zvolit Data / Seřadit. Pozor! Ikona "AZ" (objevuje se na panelu nástrojů Standardní) je ikonou Seřadit vzestupně. Doporučuji ji zaměnit za ikonu Seřadit (Nástroje / Vlastní / karta Příkazy, kategorie: Data), která má sice stejný vzhled, ale odlišnou funkci (dává na výběr kritérium řazení). Zmíněná ikona Seřadit vzestupně totiž bez vyptávání řadí záznamy podle aktivní buňky výběru, a to vzestupně. Vzniká tak dojem, že jsme spustili něco, nad čím nemáme kontrolu. 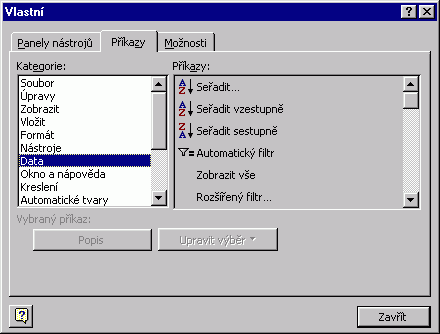 Poznámka Tip I. Tip II. |
Automatický filtrAutomatický filtr je první volbou, která nám pomůže třidit data. Najdeme ji pod menu Data/ Filtr / Automatický filtr a než ji použijeme, musíme umístit kurzor dovnitř seznamu. Excel vyhledá první řádek oblasti (naše připravená hlavička) a umístí do něj sadu ovládacích prvků (rozbalovacích nabídek). Stejným způsobem v menu volbu deaktivujeme. Klepnutím na šipku rozbalovacího seznamu v jednom ze sloupců už pak definujeme filtrování dat onoho sloupce. Dodávám, že filtrováním data neztrácíme, pouze ta nechtěná skrýváme. 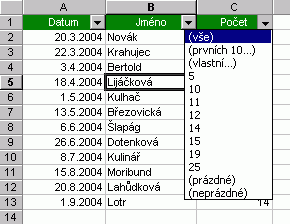 Vězte, že:
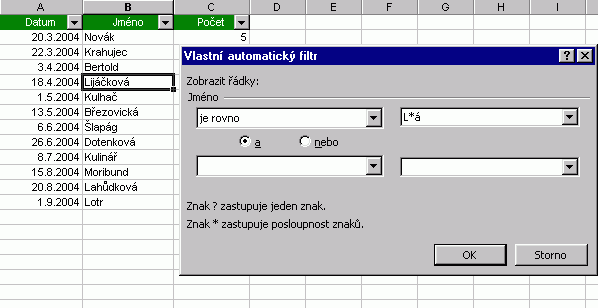 Poznámka Poznámka Dodatek  Rozšířený filtrRozšířený filtr, jak název napovídá, obsahuje více možností pro filtrování dat. Kritéria se přitom definují přímo na listu a to tím způsobem, že pro daný sloupec vytvoříme na jiném místě listu (zpravidla nad vlastním seznamem s odstupem několika řádků) stejnou hlavičku, pod níž zapíšeme kritérium. Následně umístíme kurzor do seznamu a vyvoláme dialog z menu Data / Filtr / Rozšířený filtr. . Filtrovaná data můžeme buď zpracovat přímo v seznamu, nebo výsledek přenést jinam (volba Kopírovat jinam). Do Oblasti seznamu je také zahrnuta hlavička seznamu. Vyplněný dialog ukazuje následující obrázek. 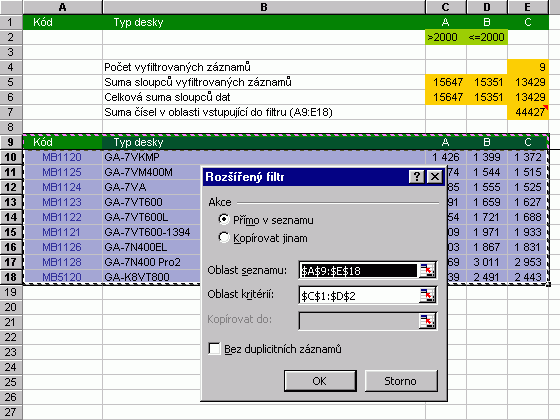
Přitom platí následující:
Z předchozího vyplývá, že pokud potřebujeme dvě podmínky pro jeden sloupec ve vztahu "A (AND)", museli bychom mít dvě hlavičky stejného názvu, pod nimiž budou v jednom řádku zapsány podmínky filtrování. A tak to také funguje. 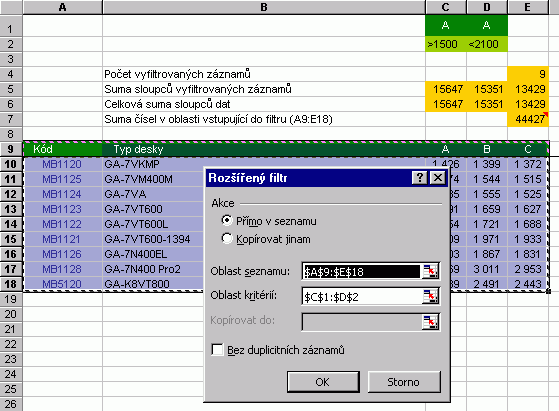 Tento příklad by bylo možné řešit i automatickým filtrem. Ten by nám ovšem neumožnil zadat více jak dvě podmínky pro jeden sloupec. Do třetice si ukážeme kombinovaný příklad, kdy má platit: A) Hodnota záznamu ve sloupci "A" je menší než 1500 nebo 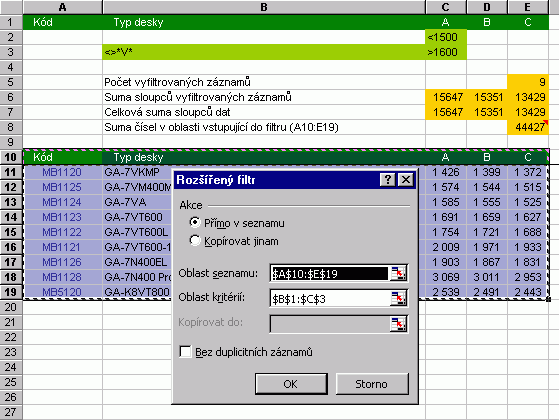 Ukázky několika zápisů obecných podmínek:
Je vidět, že i rozšířené filtrování podporuje zástupné symboly hvězdička a otazník. Pro deaktivaci filtru slouží volba Data / Filtr / Zobrazit vše. Dopočítávaná kritéria Podmínku filtrování této metody tvoří vzorec, jehož výsledkem je hodnota PRAVDA či NEPRAVDA. Použití nejlépe osvětlí příklad: 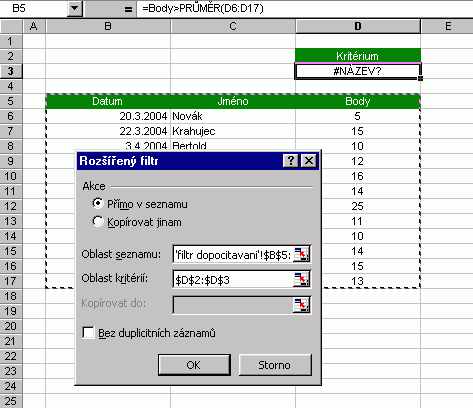 Vzorec viditelný v řádků vzorců náleží buňce D3 a svým charakterem je podobný maticovému vzorci. Odkazuje se na část seznamu spadající pod hlavičku "Body" (alternativně může ukazovat do první buňky tohoto sloupce). V tuto chvíli není podstatné, že vrací chybovou hodnotu #Název, filtr ji zpracuje správně. V dialogu je pak nutné uvažovat i hlavičku kritéria, jež nese libovolný název, ovšem odlišný od všech hlaviček vlastního seznamu. Povšimněte si také komentáře pole "Oblast seznamu:". Metodu dopočítávání je možné kombinovat s předchozími. Funkce pro filtrovaná dataFunkce "kovaná" na filtrovaná data nese název SUBTOTAL a dokáže vrátit vícero údajů o filtrovaných datech (součet, součin, běžná popisná statistika). Více se o ní dozvíte v nápovědě. Hodit se mohou i tzv. databázové funkce, mezi které patří DMAX, DMIN, DSUMA, DPOČET, DPRŮMĚR, DSOUČIN a další (zahrnuty i funkce statistické), jejichž použití je naznačeno zde: 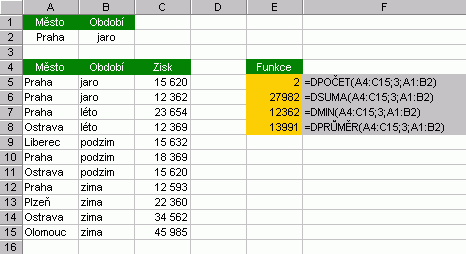 SouhrnyKaždý sběratel má čas od času potřebu počítat a škatulkovat ty své "kousky". K těmto účelům slouží nástroj Excelu, který se skrývá v menu Data / Souhrny. Stačí mít seznam podobného charakteru, jako je níže zobrazený, kurzor ponechat v oblasti seznamu a aplikovat zmíněné Souhrny. Obrázky dokumentují stav "před" a "po". 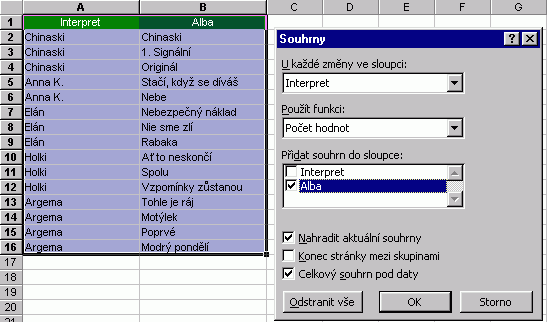
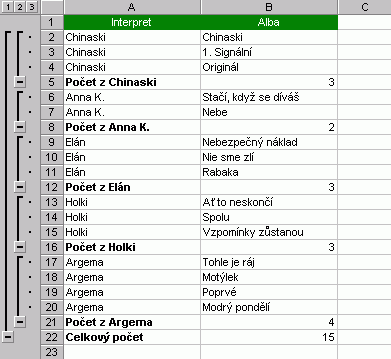
Excel vytvoří stromovou strukturu dat, jejíž zobrazení je možné ovlivnit globálně změnou zobrazení celé úrovně (zde tlačítka 1, 2, 3), nebo individuálně (tlačítka plus a mínus). Seznam můžete vrátit do původního stavu volbou Data / Souhrny / Odstranit vše. |
|||||||||||||||||||||
|
Unikátními (jedinečnými, originálními) rozumějte takové položky, resp. celé záznamy, které se vyskytují v seznamu jen jednou. Duplicitní položky (záznamy) jsou takové, které se vyskytují v seznamu vícekrát. Těžko ale určíme, co je v případě dvou stejných zápisů originál a co kopie. Dohoda neexistuje, postavit se k problému můžeme dvěma způsoby:
Ve skutečnosti nám ale nejde ani tak o to rozlišit, co je originál a co kopie, nýbrž chceme eleminovat duplicitní hodnoty, resp. separovat unikátní hodnoty. Jak na duplikátyPrvní postup využívá vzorce listu a automatický filtr. 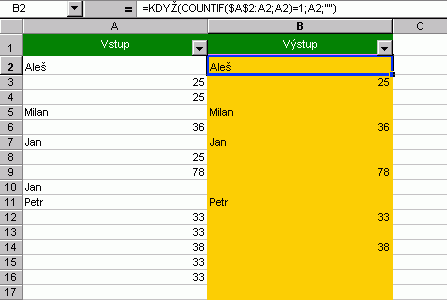 Vzorec zobrazený v řádku vzorců je zkopírován z buňky B2 tažením do buněk níže. Tak vizuálně vytřídíme originály. Dále nastoupí automatický filtr s volbou (neprázdné), který seskupí originální záznamy. Ty poté můžeme kopírováním přenést jinam. Druhý postup vychází z rozšířeného filtru a jeho podstata tkví ve ... ne neprozradím, pokud jste byli pozorní, pak už princip víte, pokud ne, vraťte se na této stránce zpět a projděte znovu všechny obrázky. Tak :-)  Ukázka je řešením kombinujícím rozšířený filtr s VBA. Kód je opět volně přístupný a makra pro tlačítka najdete pod objektem List1 (originaly II). Použita je i pojmenovaná oblast. Další obrázek ukazuje přehled vzorců pro práci s duplicitními položkami a s vyjímkou posledního sloupce se jedná o vzorce listu postavené na funkci COUNTIF. 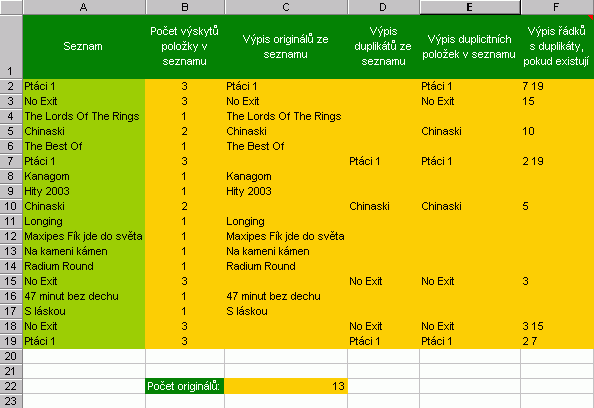 A ještě jedna technika.... 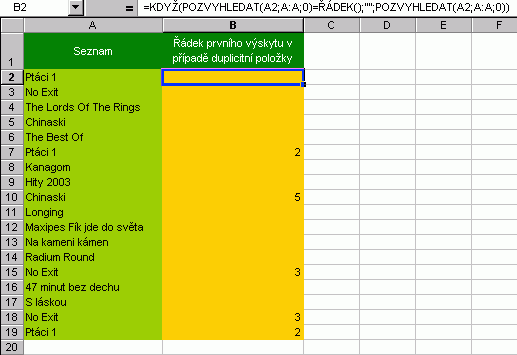 Další příklad řeší problematiku od podlahy s pomocí vlastní funkce ORIGINALY. Jedná se o funkci, která vrací matici unikátních hodnot, navíc setříděných. V prvním kroku touto funkcí zjistíme počet unikátních hodnot, v kroku druhém vybereme počet buněk odpovídající počtu unikátů a zadáme maticový vzorec pro výpis těchto položek. 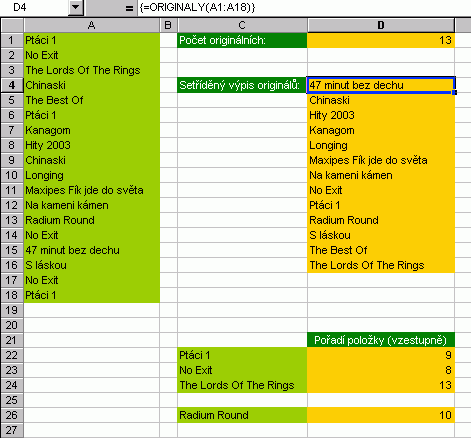 A tím pro dnešek končíme. Příště se budeme věnovat ovládacím prvkům na listu a ukážeme si řadu praktických příkladů. |