Databáze jsou určeny k tomu, abychom v nich uchovávali informace. Narozdíl od XML souborů jsou zde data uchovávána ve formě tabulek. Představme si například databázi pro knihu návštěv. Ta bude mít jednu tabulku, která bude obsahovat jednotlivé příspěvky. Takže například:
| ID | Autor | Web | Nadpis | Příspěvek | |
| 0 | Lukáš Lánský | lansky@czech-ware.net | http://www.czech-ware.net/glosar | Pochybuji | (nějaký dlouhý text) |
| 1 | Ondřej Havlíček | --- | --- | Myslím si | (nějaký krátký text) |
To je dobrý způsob ukládání dat, nemyslíte? K většině účelů se perfektně hodí. Chceme zaznamenávat určité údaje (jméno autor, jeho mail...) a podle toho si připravíme tabulku. Ta bude mít sloupce jmeno, mail atd.
Pak vytvoříme nějaký formulář, který umožní vkládání údajů uživatelem a k němu přiřadíme program, který bude vkládat do databáze nové záznamy. Záznam je jeden řádek tabulky a většinou je jich v jedné tabulce mnoho.
Je to velmi jednoduché, takovou databázi si pak můžete představit jako mnoho tabulek ve kterých je uloženo množství záznamů. Moderní databáze se ale honosí přívlastkem relační a je potřebné dozvědět se, co to vlastně znamená.
Pokud si prohlédnete libovolnou diskusi na nějakém odborném počítačovém serveru, zjistíte, že uživatelé nemluví ani tak o obsahu článku jako o jiných příspěvcích komentátorů. Vznikají dlouhé plamenné diskuse, kdy se dva moudří lidé usilovně hádají o tom, jestli je lepší Linux nebo Windows. My, co víme, že Windows se tomu jen upřímně smějeme. Tabulka pak může vypadat takto:
| ID | Autor | Web | Nadpis | Příspěvek | |
| 0 | Lukáš Lánský | lansky@czech-ware.net | http://www.czech-ware.net/glosar | Nemohu souhlasit | s ideí, že WMP je zastaralý nepoužitelný šunt. |
| 1 | Ondřej Havlíček | --- | --- | pane Lánský | ničemu nerouzumíte - WMP je šunt. |
| 2 | Lukáš Lánský | lansky@czech-ware.net | http://www.czech-ware.net/glosar | Není. | |
| 3 | Ondřej Havlíček | --- | --- | Je. | |
| 4 | Lukáš Lánský | lansky@czech-ware.net | http://www.czech-ware.net/glosar | Není. | |
| 5 | Ondřej Havlíček | --- | --- | Je. |
V tabulkách se nám hromadí hromady stejných dat. A přitom je diskuse tak podnětná a my ji nechceme rušit. Co uděláme? Vytvoříme si novou tabulku. Nazveme ji users a návštěvníky donutíme k registraci. Budeme do ní ukládat jejich data:
| ID | Jmeno | Heslo | Web | |
| 0 | Lukáš Lánský | DracoDormiensNunquamTitillandus | lansky@czech-ware.net | http://www.czech-ware.net/glosar |
| 1 | Ondřej Havlíček | osel | --- | --- |
Původní tabulky pozměníme. Už není třeba ukládat tolik dat.
| ID | AutorID | Nadpis | Příspěvek |
| 0 | 0 | Nemohu souhlasit | s ideí, že WMP je zastaralý nepoužitelný šunt. |
| 1 | 1 | pane Lánský | ničemu nerouzumíte - WMP je šunt. |
| 2 | 0 | Není. | |
| 3 | 1 | Je. | |
| 4 | 0 | Není. | |
| 5 | 1 | Je. |
Stačilo nám sem uložit odkazy na autory uložené v původní tabulce a při zobrazování diskuse budeme data vybírat z obou. To je princip relačních databází - relace je v překladu "vztah" a taková databáze je plná vztahů mezi jednotlivými tabulkami. Je to užitečné nejen díky snížení datového objemu, který bude databáze zabírat, ale i kvůli překlepům. Pokud by se uživatel v prvním příkladě jednou omylem podepsal jako "Lukšá Lánský", nezahrnovalo by následně hledáno toto jméno.
Ještě pár pojmů. "Sloupec identity" je sloupec tabulky, podle kterého můžeme rozlišit jeden záznam od druhého. V našem případě je to ID - žádné dva příspěvky v tabulce nebudou mít stejné pole ID a proto ho můžeme za sloupec identity označit. Obvykle se používá ve voláních typu prispevek.aspx?diskuse=187&prispevek=15. S tím souvisí tzv. "primární klíč" tabulky. Je to sada údajů, které jsou nutné k jednoznačné identifikaci záznamu. Pokud si vytvoříme sloupec identity, bohatě stačí on, protože u něj duplicita nehrozí, jinak se však musíme rozmyslet, jaké pole do primárního klíče zařadit, aby nikdy nemohla nastat duplicita.
Občas je složité přijít na nejlepší rozvržení dat v tabulkách. Postupu, při kterém se navrhuje optimální struktura databáze, se říká normalizace. Nebudu se jím zde příliš zabývat, protože na většinu úloh stačí troška selského rozumu, ale pokud se chcete poučit, prostudujte si například dokument Normalizace databáze.
Jsou různá řešení. Projděme si některé.
- MS SQL je poměrně kvalitní a hodně drahá databáze od firmy Microsoft. Při přístupu k ní přes ASP.NET máme velkou výhodu - můžeme se k ní připojit zabudovanými metodami, což zvýší rychlost naší aplikace. Další její výhoda spočívá v existenci produktu MSDE, který je zadarmo a jehož instalaci jsme si popsali v prvním díle.
- MySQL databáze se používá zejména v kombinaci s PHP. V ASP.NET ji můžeme opomenout a to zejména ze dvou důvodů:
- Museli bychom k ní přistupovat skrze OLE DB, což je pomalé a navíc drivery k ní nejsou prý zrovna kvalitní
- Někteří lidé jí nemají rádi, protože nenabízí zdaleka tolik možností jako MS SQL a Oracle
- Access je databáze založená na souborech. Je to většinou dobrá forma pro začátečníky (mohou si ve stejnojmenné aplikaci, která je součástí Office, databázi pohodlně vytvořit), ale pro navštěvovanější projekty se nehodí, neboť by mohly nastat kolize mezi přístupy jednotlivých uživatelů při přístupu k souboru.
Databázový program je samostatný systémem, ke kterému se z vaší stránky připojíte, zašlete příkazy a očekáváte odpověď. Může běžet i na jiném počítači - běžně se to tak děje. Otázkou je, v jakém že jazyce budete databázi zasílat pořadavky.
V SQL - Structured Query Language (strukturovaný dotazovací jazyk). Trochu se podobá anglické mluvené řeči, je opravdu docela "lidský". Projdeme si pár základních příkazů:
SELECT sloupce k navrácení FROM název tabulky WHERE podmínka výběru záznamů ORDER BY řadící výraz
SELECT je patrně nejpoužívanější příkaz, se kterým se budete setkávat. Vybírá data z databáze. Má čtyři hlavní parametry:
- sloupce k navrácení - pokud budete ve stránce potřebovat třeba jenom ID daného záznamu, je zbytečné, aby byly vráceny všechny údaje daného záznamu. Zde buď zadat hvězdičku (tím říkáte, aby byly zaslány všechny sloupce) nebo vyjmenovat potřebné hodnoty v tomto formátu: ID, jmeno, heslo.
- název tabulky - zadáte název tabulky, v které chcete vyhledávat
- podmínka výběru záznamů - může být značně složitá, v příštím díle se seznámíme s některými dalšími možnostmi. Prozatím stačí vědět, že můžete zadat podmínku typu ID = 15, kde ID bude pole z právě zkoušeného záznamu a sloupce ID. Samozřejmě můžete používat logické operátory AND a OR.
- řadící výraz - podle něj budou výsledky sežazeny. Uvedeme do něj seznam sloupců, podle kterých bude řazení prováděno a pomocí slova ASC nebo DESC určíme, zda řadit ve směru a - z nebo z - a.
Takže například chceme získat ID a mail uživatele se jménem "Lukáš Lánský" z tabulky users seřazené podle ID:
SELECT ID, mail FROM users WHERE jmeno = 'Lukáš Lánský' ORDER BY ID ASC
INSERT INTO název tabulky (seznam sloupců) VALUE (seznam nových hodnot)
Insertem vložíte nový záznam do databáze. Tady bude myslím stačit příklad:
INSERT INTO users (jmeno, heslo, mail, web)
VALUES ('Lukáš Lánský','DracoDormiensNunquamTitillandus',
'lansky@czech-ware.net','http://www.czech-ware.net/glosar')
UPDATE název tabulky SET název sloupce = nová hodnota WHERE podmínka
Příkaz Update provádí samozřejmě aktualizici již existujících záznamů. Opět příklad mluví za vše:
UPDATE users SET mail = 'lansky@ware-czech.net', web = 'www.ware-czech.net/glosar'
WHERE jmeno = 'Lukáš Lánský'
DELETE FROM název tabulky WHERE podmínka
Pokud vynecháte část WHERE, smažete si celou tabulku. Jinak budou samozřejmě smazány pouze záznamy vyhovující podmínce ... mazání je tedy asi ta nejjednodušší činnost.
DELETE users WHERE jmeno = 'Lukáš Lánský'
Pro práci s ní musíme nejdříve vytvořit spojení. Zaprvé potřebujeme tzv. connection string. To je řetězec obsahující údaje potřebné k připojení se k databázi. My jsme si v prvním díle našeho seriálu nainstalovali MSDE, náš conn. string pro připojení k lokální databázi bude vypadat asi takto:
Data source=localhost;initial catalog=chip;user id=sa;
password=DracoDormiensNunquamTitillandus
Password (heslo) jste nastavili při instalaci MSDE. Initial catalog značí jméno databáze, s kterou budeme pracovat - vytvořili jsme ji v prvním díle. Musíme také spustit MSDE engine, SQL Server Service Manager najdeme přibližně na této cestě: D:\Program Files\Microsoft SQL Server\80\Tools\Binn\sqlmangr.exe.
Když už jsme u toho, rovnou spusťte program ASP.NET Web Matrix, která jsem také tehdy instalovali. Ten vám umožní vytvořit první zkušební tabulku. Jaké to bude překvapení, že bude pojmenovaná "users". Stačí rozbalit databázi, kliknout na složku Tables a zvolit příkaz New Database Object. Podívejte se na nastavení jejích sloupců:
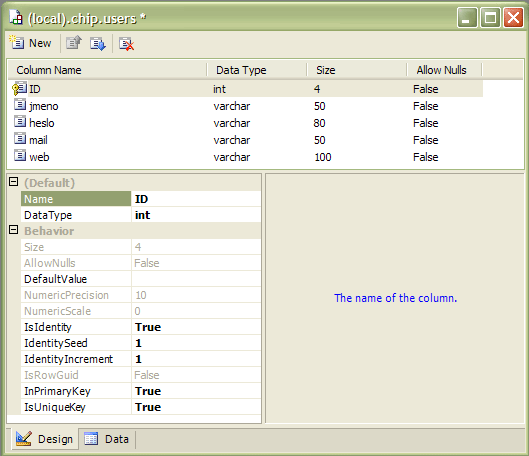
Dialog uzavřeme a už se opravdu můžeme věnovat .NETu. ConectionString využijeme takto:
Dim conn As System.Data.SqlClient.SqlConnection = New
System.Data.SqlClient.SqlConnection("Data source=localhost;initial catalog=chip;
user id=sa;password=DracoDormiensNunquamTitillandus")
conn.Open()
Vytvořením objektu SqlConnection a zavoláním jeho metody Open jsme otevřeli danou databázi. Pokud bychom nevyužívali MS SQL, využívali bychom namespace System.Data.OleDb - všechno by ale bylo velmi podobné.
Co dál? Nabízí se více možností pro práci s databází. Dnes si projdeme jenom ten první, který je z nich nejrychlejší, ale nenabízí mnoho komfortu pro programátora. Příště si ukázeme DataSet a jeho svázání se serverovými ovládacími prvky.
Takže teď vytvoříme objekt SqlCommand, který stejně jako SqlConnection najdeme ve jmenném prostoru System.Data.SqlClient. Má několik přetížení konstruktoru, nejpoužívanější je asi takováto kontrukce:
Dim cmd As SqlCommand = new SqlCommand("SELECT * FROM users WHERE id = 1", conn)
Jako první parametr tedy String obsahující SQL dotaz, jako druhý objekt připojení k databázi. Co dále? Otázkou je, jaký typ příkazu jsme uvedli. Pokud jde o Select, budou vrácena nějaká důležitá data a zavoláme metodu ExecuteReader, která je bez parametrů. Vrací objekt SqlDataReader, což je právě ta nejrychlejší a nejprimitvnější cesta čtení tabulky.
Pokud jsme však uvedli INSERT, UPDATE nebo DELETE, nebudou vrácena žádná data. Zavoláme tedy metodu ExecuteNonQuery, která je taktéž bez parametru a vrací počet záznamů, kterých se dotkl náš příkaz.
Nezapomínejte však na uzavření objektu připojení k databázi vždy po skončení práce. Tedy zavolání metody Close. Pokud byste tak neučinili, hromadila by se ve vaší aplikaci neaktivní připojení, což by vedlo k snížení jejího výkonu.
Ještě se vrátíme k objektu SqlDataReader. Jak se z něj čtou data? Klíčová je metoda Read, po jejímž zavolání se při prvním použití načte první záznam a při dalších se přesuneme na záznamy další. Metoda vrací hodnotu boolean, která značí, jestli jsme se opravdu přesunuli dále (true) nebo zda už není žádný další záznam (false). Toho se nechá dobře využít v cyklu While, kde můžeme testovat na tuto hodnotu a zároveň se posouvat k dalším záznamům.
Pokud máme načtený některý záznam, jak ale zjistíme hodnoty jednotlivých polí? Objekt má navíc ještě množství metod typu GetByte, GetDouble, GetBoolean, GetString atp. Ty mají v parametru jednu funkci, kterou sdělíme, který že sloupec tabulky nás zajímá. Takže příklad výpisu z tabulky users:
Dim conn As SqlConnection = new SqlConnection(connStr)
Dim cmd As SqlCommand = new SqlCommand("SELECT * FROM users", conn)
Dim reader As SqlDataReader = SqlCommand.ExecuteReader()
Response.Write("<table>")
While reader.Read()
Response.Write("<tr><td>" + reader.GetInt32(0))
' ID uživatele
Response.Write("<td>" + reader.GetString(1))
' Uživatelské jméno
Response.Write("<td>" + reader.GetString(2))
' Heslo
Response.Write("<td>" + reader.GetString(3))
' Mailová adresa
Response.Write("<td>" + reader.GetString(4))
' Webová adresa
End While
Response.Write("</table>")
conn.Close()
Tak, to by stačilo. Tento typ výstupů byl běžný v ASP programech, v .NETu se již k těmto účelům používají sofistikovanější metody. Pokud jde o zobrazování dat, je mnohem mnohem výhodnější používat serverové ovládací prvky. SqlDataReader používejte jen v situacích, kdy vaše aplikace potřebuje rychle pro svoji potřebu natáhnout z databáze nějaký údaj.
V dnešní části jsme se jen lehce dotkli problematiky databází a prakticky vůbec jsme neodkryli nové .NET metody k přístupu a hlavně zobrazování dat. Ty si představíme příště.
Veškeré náměty, dotazy a připomínky pište na adresu lansky@czech-ware.net.