
One of the major requirements that InterMail fulfills
is high availability, which means that the system must be
available and functioning properly at all times.
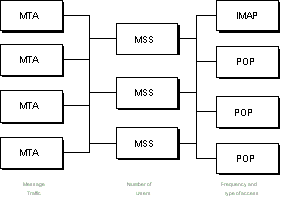
Figure B: the recommended high availability and
reliability features for each of the server types.
Server Redundancy
Server redundancy simply means that more than one server
is made available to fulfill a function. The first and
third axes of Figure A (MTAs and client access servers),
as well as the directory, employ server redundancy. The
system is configured so that there are more machines than
necessary to handle the expected traffic, so that if one
of the machines fails, the other machines will
accommodate the load until the first machine is brought
back online. The distribution of load among the machines
is handled by DNS using a round-robin mechanism. When a
machine fails, it is removed from the DNS rotation and
then reintroduced when it is brought back online.
Failover
Failover is employed for the MSS machines, which host
data that must be accessible at all times. In order to
insure continuous access, "hot spare" machines
are deployed. If an MSS machine fails, the hot spare will
assume the network identity of the failed machine and
access its disk array through the second port.
Failover is provided by third party software and is not part of InterMail itself. There are two facets to supporting failover. The first is the actual monitoring of the hardware itself so that failures can be detected. The second is a set of scripts that will be executed if a failure occurs. These scripts will cause the switch-over to a partially booted machine (which allows the IP address of a failed machine to be assumed by the spare machine). The spare machine assumes the identity of the failed machine, connects to the disk array through a second port, and appears on the network to replace the MSS that failed.
Note: While Software.com recommends the use of a failover mechanism, it is not required by InterMail.
Messaging data must be recoverable in the event of a disaster situation such as a hardware crash. Although it is not required, Software.com highly recommends server disk mirroring, journaling, and online backups. The following is an overview of each:
Disk Mirroring
Disk mirroring protects data integrity; all critical
disks are mirrored to insure that data will always be
accessible. In the event of a disk failure, the mirror is
immediately placed into service, providing uninterrupted
access to the data. "Hot spare" disks in the
storage array are brought up to date with their mirrors.
With this mechanism, single points of disk failure are
eliminated.
Journaling
InterMail uses file-level and application-level
journaling to provide rapid and graceful system recovery.
A journaling file system enables quick recovery of the
file system used for storing message bodies.
Application-level journaling enables the recovery
procedure to roll the file system and the database
forward to the most recent consistent state, ensuring
that no message transactions are lost.
Online Backup and Recovery
To further insure against loss of data, online backups
are performed while systems continue to fulfill their
normal duties without interruption. Snapshots are taken
on standard schedules for full and incremental backups,
and this is the data that will be used in disaster
recovery scenarios. (This level of data backup is applied
to the message stores; the mail queue data on the MTAs
are backed up by the use of disk mirrors.)
Learn more about InterMail: Management and Administration
Home Page | Post.Office | InterMail | Visit Software.com's Web Site