 |

|
|
|
|
|
|
// LinuxTag 2004
Besuchen Sie uns auch nächstes Jahr wieder auf dem LinuxTag 2004
im Karlsruher Messe- und Kongresszentrum. Für nähere Details und den
genauen Termin besuchen Sie bitte die LinuxTag Homepage.
|
|
|
|
|
|
|
|
EUROPAS GRÖSSTE GNU/LINUX MESSE UND KONFERENZ
KONFERENZ-CD-ROM 2003 |
|
|
|
|
|
|
| Hauptseite // Vorträge // gUSA: User Space Atomicity with Little Kernel Modification |
|
|
gUSA: User Space Atomicity with Little Kernel Modification
Yutaka Niibe
Abstract
The design and implementation of gUSA ("g" User
Space Atomicity) is provided. gUSA offers efficient atomicity
in user space. It is designed for uni-processor system and has
been implemented in GNU/Linux for embedded processors: SuperH (SH-3,
SH-4), MIPS 5900 and StrongARM. It can be used effectively for
the implementation of thread libraries, such as ntpl. It is
efficient and useful for processors with poor hardware support
of atomic operations.
The scheme is simple and powerful, it could be applied to
other kinds of UNIX, too.
Introduction
gUSA is a little hack to provide a guaranteed atomic sequence in user
space for uni-processor systems. It has been invented when I was
hacking for the GNU/Linux on SuperH Project. It consists of the ABI extension
in user space and the kernel modification.
In this section, we explain the background where gUSA is needed:
thread programming and embedded processors. Then, features of gUSA
are provided.
The needs of thread programming for embedded systems
The thread programming model is useful. It is not only for high
performance SMP (Symmetric Multi-Processing) servers which handle
hundreds of transactions per seconds, but for embedded
systems too. Consider the software of a portable audio
player with flash memory. It is quite natural to have an audio playing
thread, a user interface thread, and a USB control thread. Although
multi-threaded applications with high load are not practical for
uni-processor embedded systems, the use of threads should not be denied.
Thread programming has evolved - many programming languages
support threads, even some middle-ware (e.g. GUI toolkits) assumes the
use of threads. So, it is good if we have better support of threads
for uni-processor systems with embedded processors.
The mutual exclusion within the kernel was discussed in many papers
and books [MODERNUNIX][UNIXINTNL], but user space is the issue here.
Thread support in embedded processors
For thread programming, in the lowest level, the key technology is
atomicity, that is, atomic operation or atomic
sequence. The atomicity guarantees that it is executed with no
intervention.
Using atomicity, mutual exclusion primitives (such as mutex,
condition-variable, etc.) are constructed. Mutual exclusion
primitives form the base of thread libraries and threaded
applications. With those primitives, we can guarantee how threads
work independently or cooperatively with no bad interference. It is
required that not only the primitives work correctly and consistently,
but also that they work efficiently (both in cycles and instruction
sequence).
Rich processors have hardware support for SMP, they have instructions
for atomic sequences such as ll/sc (Load Locked / Store Conditional),
and it is possible to construct efficient primitives with them [CAAQA].
However, among embedded processors, the hardware support of atomicity
tends to be poor. (This is because such processors are not targeted
for multi-processor systems and the constraint on hardware resources is
crucial in the design of embedded processors.)
For example, in terms of atomicity, the SuperH architecture only has the TAS
(test-and-set) instruction, the MIPS 5900 has nothing, the ARM architecture
only has the SWP (data-swap) instruction, while the Thumb instruction set of
ARM has nothing.
M32R has the LOCK instruction, but it really holds a memory bus (since the
impact to a system would be huge, the use of the LOCK instruction should be
strictly limited to special cases. It is not for user space either).
When there is no or less support by hardware, the software should
implement something. There were some non-general and/or inefficient
ways to do that:
System calls for mutual exclusion primitives:
Implement mutual exclusion primitives in kernel space and offer them
as system calls.
Instruction emulation of ll/sc:
Emulate ll/sc by kernel on handling of invalid opcodes of
corresponding operations (or offer system calls of ll/sc).
Use of a special device: /dev/test [PS2LINUX]
Those are not solutions, in fact. Those are not general, some require
much kernel modifications, or are quite specific to a processor. Besides,
they are inefficient.
Thus, it has been common that the engineers avoided the use of threads for
embedded systems, because the implementation of multi-threaded
applications, if not impossible, used to be bigger and less efficient,
or because the system was difficult to maintain as it came with
a special jumbo kernel patch.
The features of gUSA
gUSA enables multi-threaded applications for embedded processors. With
gUSA, atomicity in user space is quite easy and efficient. No special
system calls, no special devices are required.
gUSA is a simple and powerful scheme, it is efficient in runtime and there
is little overhead in instruction space. Furthermore, it has
the following features:
-
Gentle:
It requires little kernel modification, the modification is easy to implement.
The impact of the modification is small and negligible.
-
General:
It is as general as the ll/sc instructions, thus we can implement
many forms of mutual exclusion primitives with this scheme.
-
Generic:
It can be applied to many processors. Almost all modern architectures
could adopt gUSA.
Design
Atomic sequence is the one which is executed atomically, with no
intervention.
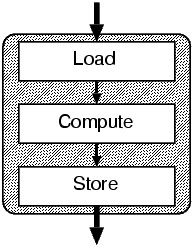
Without loosing generality, the atomic sequence can be defined as it
consists of three steps: "Load", "Compute", and
"Store". At the step "Load", some data is
loaded into a register. At the step "Compute", computation
is performed, and then, data is stored into memory at the step
"Store".
Our problem to solve is: how to guarantee "atomic sequence"s
to be executed correctly.
Thinking about the atomic execution of the
sequence, we might want to the following:
Guarantee the sequence not to be interrupted.
However, it is in general difficult to disable interrupts in user space.
Even if it were possible, it would not be efficient enough.
Then, thinking about the consistency of the data
and how ll/sc works in the supported hardware, the requirement can be
weakened as:
The data "Store"-ed should be the one which is not to be
interrupted.
This means, it is OK that the sequence is interrupted, it is OK that
"Load" and "Compute" can be executed multiple
times. All that we care about is the data "Store"-ed, which
should be the result of atomic execution.
This requirement can be implemented efficiently, as illustrated
in the figure.
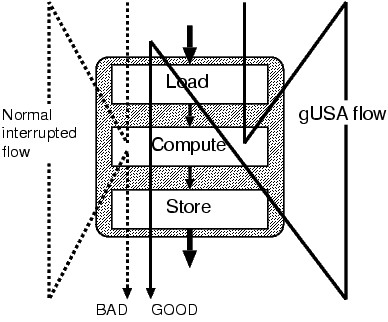
The dotted line shows the control flow which may result in BAD
consistency. The solid line shows the control flow of gUSA, which
guarantees the consistency (GOOD). The principle is simple enough, it
can be expressed in one word: "rewind". Longer expression is the
following:
When the atomic sequence is interrupted in its execution, restart the
sequence from the beginning.
The "rewind" can be done by the kernel, after it interrupts
the execution of the atomic sequence. To support the kernel's rewinding
of the execution, we need to extend the ABI (Application Binary
Interface) of the processor:
Identification of atomic sequences is easily implemented. For example,
an abnormal condition such as "stack pointer does not point to a
valid address of user space" can be used to specify an atomic
sequence. Identification of rewind point(s) can be implemented as the
definition of registers (or stack slot) usage of an atomic sequence.
The kernel does not need to check all the cases of interrupts (it does not
handle gUSA in case of hardware interrupts by drivers). For UNIX,
the kernel should only handle the following two points:
Thus, the modification of the kernel for gUSA is minimal. In the case of
Linux, it affects only two points of architecture specific parts:
"handle_signal" and "reschedule". No extension of
the semantics of processes or threads is required. No pseudo driver is
required. No special resource is consumed for the support of gUSA,
it is only a slight change in the kernel.
For user space, as the principle is simple enough, it is efficient.
And the scheme is general enough, like the ll/sc instructions, it can be
used for many forms of mutual exclusion primitives.
Furthermore, this scheme is considered generic, almost all modern
architectures could adopt gUSA.
Implementation
In GNU/Linux system, I've implemented gUSA for many architectures:
SuperH (SH-3, SH-4), MIPS R5900, and StrongARM. In this section, each
implementation is described. The code are provided as the appendix,
as the example usage, atomic add (gUSA_exchange_and_add) is provided
for each architecture, as well as kernel modifications required.
For the identification of atomic sequences, the minus value of the
stack pointer (as signed integer) is used. This is common for all
architectures.
For each architecture, two rewind points are defined, one for the
signalled rewind point, and another is the preempted rewind point. This
is because the signal handler should be called with normal conditions
(stack pointer restored with original value).
When an atomic sequence has been interrupted (say, by SIGALRM), the signal
handler is called. In this case, the signal handler itself should not be
treated as atomic sequence, thus, we need to reset the stack pointer to the
original value before calling the signal handler. After the signal handler,
the control of flow should go to signalled rewind point, where
the stack pointer will be set (to minus value) again.
SuperH (SH-3, SH-4) implementation
The SuperH processor has the TAS (test-and-set) instruction, but there is no
general atomicity support such as ll/sc. Mutual exclusion primitives
can be constructed with TAS, but a more efficient implementation is
possible with gUSA. The ABI extension is the same for SH-3 and for SH-4.
The kernel modifications are the same too.
The extension of the ABI for atomic sequences is as follows:
-
Stack pointer "r15;" has minus value (as singed integer),
where the absolute value indicates the size of the sequence.
-
Register "r0;" has the exit point of the sequence.
-
Register "r1;" has the value of the original stack pointer.
Two rewind points are defined as follows:
-
Signalled rewind point:
The point is yield as summation of register "r0" and stack pointer
"r15" minus two (one instruction above).
-
Preempted rewind point:
The point is yield as summation of register "r0" and stack pointer
"r15".
We need to care about alignment in the implementation of the atomic
sequence. For example, in gUSA_exchange_and_add, the exit point of
the sequence should be 4-byte-aligned, "nop" is used for
this purpose.
MIPS 5900 implementation
The MIPS R5900 processor has no atomicity instruction at all. So, gUSA is
quite useful. In the appendix, test-and-set functionality is
demonstrated as well as gUSA_exchange_and_add.
The extension of the ABI is as follows:
-
Stack pointer "sp" (r29) has minus value (as singed
integer), where the absolute value indicates the size of the
sequence.
-
Register "t0" has the exit point of the sequence.
-
Register "t1" has the value of the original stack pointer.
Two rewind points are defined as follows:
-
Signalled rewind point:
The point is yield as summation of register "t0" and stack pointer
"sp" minus four (one instruction above).
-
Preempted rewind point:
The point is yield as summation of register "t0" and stack pointer
"sp".
StrongARM implementation
The StrongARM processor has the SWP (data-swap) instruction, but there is no
general atomicity support such as ll/sc. Mutual exclusion primitives
can be constructed with SWP, but more efficient implementation is
possible with gUSA.
The extension of the ABI is as follows:
-
Stack pointer "sp" has minus value (as singed
integer), where the absolute value indicates the size of the
sequence.
-
Register "r0" has the exit point of the sequence.
-
Register "r1" has the value of the original stack pointer.
Two rewind points are defined as follows:
-
Signalled rewind point:
The point is yield as summation of register "r0" and stack pointer
"sp" minus four (one instruction above).
-
Preempted rewind point:
The point is yield as summation of register "r0" and stack pointer
"sp".
Evaluation
In order to evaluate the gUSA implementations, and to validate the
usefulness of the scheme, two experiments have been done. One is
checking the impact of the kernel modification, another is a performance
benchmark of user space atomic sequences.
The impact of the kernel modification
The kernel modification required for gUSA is small, as is shown in the appendix.
The changes are at two points: handle_signal and reschedule. Both are
relatively heavy functionality, and few instructions are added there,
thus, the performance loss is considered not much, at least in theory.
With a Debian GNU/Linux system on SuperH (SH-3, SH-4), the benchmark has
been executed using lmbench-2.0-patch2-2 and got indexes of
"Processor, Processes" and "Context switching".
Two kernels have been tested: a plain kernel and a kernel with gUSA
modification. The benchmark has been executed three times for
the plain kernel, nine times for the gUSA kernel. The result is shown
in the appendix.
In this experiment, almost no performance loss was detected.
The only small impact of gUSA has been proven.
Performance benchmark
As the scheme of gUSA is simple enough, it is expected that the
implementation of atomic sequences by gUSA results in good performance.
For the performance benchmark, the simple test program "eaa.c"
(exchange_and_add) is written to compare multiple implementations, and
it is tested on an SH-4 Debian system and on a MIPS 5900 PS2 Linux system.
The benchmark measured the elapsed time (lower is better).
In the benchmark, there are three parameters: O, T, and TYPE. Atomic
addition is executed on objects (the number of objects is O), and each
object has T threads. The number of threads in the application is
OxT. TYPE specifies the implementation of the atomic addition:
-
TYPE 0: gUSA
-
TYPE 1: test-and-set (single lock)
-
TYPE 2: test-and-set (distributed lock)
-
TYPE 3: system call
-
TYPE 4: test-and-set (/dev/test single lock)
-
TYPE 5: test-and-set (/dev/test distributed lock)
TYPE 0 uses a gUSA atomic sequence. TYPE 1, 2, 4 and 5 use test-and-set
as the atomic operation, and construct atomic addition with that.
TYPE 1 shares a single lock variable among threads, while TYPE 2 has O
individual lock variables. TYPE 3 is an implementation by system call.
TYPE 1, 2 and 3 are meaningful for SuperH (they use the TAS instruction for
the test-and-set operation). For MIPS 5900, TYPE 3 is not supported,
there are two test-and-set variations, one is gUSA (TYPE 1 and 2),
another is the one using /dev/test (TYPE 4 and 5).
The results are shown in the following tables.
User space performance test (eaa.c) for SH-4 [sec]
| TYPE \ (O,T) |
(1,1) |
(2,2) |
(4,4) |
(8,8) |
| 0 (gUSA) |
0.986 |
4.71 |
18.9 |
76.5 |
| 1 (TAS 1) |
2.14 |
17.6 |
191 |
2710 |
| 2 (TAS O) |
2.19 |
12.2 |
76.7 |
555 |
| 3 (SYSCALL) |
4.68 |
19.7 |
95.5 |
347 |
User space performance test (eaa.c) for MIPS 5900 [sec]
| TYPE \ (O,T) |
(1,1) |
(2,2) |
(4,4) |
(8,8) |
| 0 (gUSA) |
0.869 |
3.47 |
13.9 |
55.4 |
| 1 (TAS gUSA 1) |
1.12 |
6.53 |
69.1 |
688 |
| 2 (TAS gUSA O) |
1.13 |
4.73 |
26.4 |
151 |
| 4 (TAS /dev/test 1) |
1.37 |
9.81 |
84.6 |
1060 |
| 5 (TAS /dev/test O) |
1.41 |
6.33 |
36.9 |
203 |
For all cases, gUSA shows best performance. When contention
occurs, distributed locks shows better performance than a single lock.
The system call implementation is sometimes useful. For the test-and-set
implementation, specifically, gUSA implementation is superior over
/dev/test implementation.
Discussion
In this section, we discuss the usefulness of gUSA and its limitations.
Note on porting gUSA to other processors
Speaking for Linux, the part of modification is considered same, the
ABI extension will be similar, too.
The choice of registers for the ABI extension would be important for some
architectures, for example, some care would be needed for choosing
a suitable register to have the address for the exit point of the atomic
sequence.
The encoding of the size of the atomic sequence might matter.
In any cases, the porting to other processors will be easy.
Note on the ABI extension in user space
gUSA extends the ABI in user space programs. In the implementations,
the stack pointer has an abnormal value in the atomic sequence. This
means, users will not be allowed to use the stack pointer for other
purposes, such as saving temporal values of computation. Doing that,
the control of flow might jump to an unexpected point when the execution
is interrupted.
This restriction (of not allowing use of the stack pointer) does not
matter in usual programming. Only assembler programmers can abuse
the stack pointer, but there is virtually no useful usage, in fact.
So, the ABI extension is considered safe.
Security
The use of gUSA should not introduce system security issues.
Programmers could maliciously change the value of the stack pointer, but
it cannot affect the execution of the kernel or other processes, the
effects are limited to the execution of the thread in question.
Thread library
The atomic sequence of gUSA can be used for a thread library using
kernel threads (such as LinuxThreads and ntpl), as well as
a thread library in user space (such as Pth).
Live lock
There is a possibility that the atomic sequence results in a live lock,
that is, the control of flow loops in the atomic sequence and
never exits. If the computation is so complex and preemption
occurs every time, a live lock occurs.
If the atomic sequence has so complex computations, it is a problem
anyway, not only for gUSA use. Such complex computations should be
avoided in atomic sequences and/or in mutual exclusion, in general.
Atomic store requirement
gUSA depends on the processors supporting atomic store. If this
condition does not match, it means that it is possible for
"Load" to fetch inconsistent data, partially
"Store"-ed.
For the processors in actual use, atomic store is guaranteed in some
way, provided we keep the constraint of length of data and aligenment.
Thus, this issue could be no problem.
UNIX
gUSA is a general scheme, there is no reason why it cannot be applied to
other operating systems. It could be applied to UNIX in general, easily.
Contradictory kernel features of Linux
gUSA cannot co-exist with the PREEMPTIVE kernel. gUSA depends on the
fact that the context switch occurs only at "reschedule".
The PREEMPTIVE kernel puts many preemption points in kernel and the
context switch occurs at many places (that is the feature!), so, the
precondition of gUSA breaks, correct behavior is not guaranteed.
Conclusion
We have shown the scheme of gUSA, the design and implementation. The
experiments show the efficiency and no negative impact of gUSA,
and we discussed its usefulness and limitations.
We could say that gUSA is a clever invention. The modification of the
SuperH kernel has been adopted, and the SuperH implementation has been
merged into the GNU C library.
With gUSA, we hope the use of thread programming will become popular
for embedded systems. With gUSA, GNU/Linux can offer a seamless
environment for cross development, in terms of thread programming.
Lastly, I'd like to acknowledge much help of various people. The birth of
gUSA has been helped by Kazumoto Kojima and Akira "akr"
Tanaka. Without the discussion with them, gUSA would not be here. For the
implementation of gUSA, my thanks go to Greg Banks, Ulrich Drepper,
and Satoru Tomura. Their experiences and criticisms were valuable,
and gUSA became sophisticated. For the performance benchmark, I got
help for development environments of SuperH, MIPS 5900, and StrongARM,
by Takeshi Yaegashi, Masanori Goto, and Takatsugu Nokubi. Thanks all.
Happy Hacking, Everyone. Enjoy gUSA.
References
[MODERNUNIX] Curt Schimmel,
UNIX Systems for Modern Architectures: Symmetric Multiprocessing and
Caching for Kernel Programmers,
Addison-Wesley, 1994.
[UNIXINTNL] Uresh Vahalia, UNIX Internals :The New Frontiers,
Prentice-Hall, 1996.
[CAAQA] John L. Hennessy, David A. Patterson,
Computer Architecture -- A Quantitative Approach (2nd ed.),
Morgan Kaufmann Publishers, 1996.
[PS2LINUX] Hiroyuki Machida, Takao Shinohara,
Secure user-level mutual exclusion in PS2 Linux,
Linux Conference 2001, September 2001 (In Japanese).
Appendix
Example of user space: SuperH
static int
gUSA_exchange_and_add (volatile int *mem, int val)
{
unsigned long dummy;
int result;
__asm__ (".align 2\n\t"
"mova 1f,r0\n\t"
"nop\n\t"
"mov r15,r1\n\t"
"mov #-8,r15 ! critical region start: rewind point #1\n"
"0: mov.l @%2,%0 ! rewind point #2\n\t"
"mov %3,%1\n\t"
"add %0,%1\n\t"
"mov.l %1,@%2\n"
"1: mov r1,r15 ! critical region end"
: "=&r" (result), "=&r" (dummy)
: "r" (mem), "r" (val)
: "memory", "r0", "r1");
return result;
}
|
Kernel Modification: SuperH
2002-08-15 NIIBE Yutaka <gniibe@m17n.org>
gUSA ("g" User Space Atomicity) support.
* arch/sh/kernel/signal.c (handle_signal): Added gUSA handling.
* arch/sh/kernel/entry.S (reschedule): Added gUSA handling.
--- linux-2.4.18.superh.no-gusa/arch/sh/kernel/entry.S Wed Aug 14 08:54:12 2002
+++ linux-2.4.18.superh.gusa/arch/sh/kernel/entry.S Thu Aug 15 23:14:47 2002
@@ -94,6 +94,7 @@ OFF_R5 = 20 /* New ABI: ar
OFF_R6 = 24 /* New ABI: arg2 */
OFF_R7 = 28 /* New ABI: arg3 */
OFF_SP = (15*4)
+OFF_PC = (16*4)
OFF_SR = (16*4+8)
OFF_TRA = (16*4+6*4)
@@ -455,12 +456,28 @@ __INV_IMASK:
.align 2
reschedule:
+ ! gUSA handling
+ mov.l @(OFF_SP,r15), r0 ! get user space stack pointer
+ mov r0, r1
+ shll r0
+ bf/s 1f
+ shll r0
+ bf/s 1f
+ mov #OFF_PC, r0
+ ! SP >= 0xc0000000: gUSA mark
+ mov.l @(r0,r15), r2 ! get user space PC (program counter)
+ mov.l @(OFF_R0,r15), r3 ! end point
+ cmp/hs r3, r2 ! r2 >= r3?
+ bt 1f
+ add r3, r1 ! rewind point #2
+ mov.l r1, @(r0,r15) ! reset PC to rewind point #2
+ !
+1: mov.l 2f, r1
mova SYMBOL_NAME(ret_from_syscall), r0
- mov.l 1f, r1
jmp @r1
lds r0, pr
.align 2
-1: .long SYMBOL_NAME(schedule)
+2: .long SYMBOL_NAME(schedule)
ret_from_irq:
ret_from_exception:
--- linux-2.4.18.superh.no-gusa/arch/sh/kernel/signal.c Wed Aug 14 08:54:12 2002
+++ linux-2.4.18.superh.gusa/arch/sh/kernel/signal.c Wed Aug 14 17:50:56 2002
@@ -533,6 +533,17 @@ handle_signal(unsigned long sig, struct
case -ERESTARTNOINTR:
regs->pc -= 2;
}
+ } else {
+ /* gUSA handling */
+ if (regs->regs[15] >= 0xc0000000) {
+ int offset = (int)regs->regs[15];
+
+ /* Reset stack pointer: clear critical region mark */
+ regs->regs[15] = regs->regs[1];
+ if (regs->pc < regs->regs[0])
+ /* Go to rewind point #1 */
+ regs->pc = regs->regs[0] + offset - 2;
+ }
}
/* Set up the stack frame */
|
Example of user space: MIPS 5900
.text
.align 3
.globl gUSA_test_and_set
.ent gUSA_test_and_set
.set noreorder
gUSA_test_and_set:
li $3, -1
la $8, 1f
move $9, $sp
li $sp, -8 # critical region start: rewind point #1
0: lw $2, ($4) # rewind point #2
sw $3, ($4)
1: move $sp, $9 # critical region end
j $31
nop
.end gUSA_test_and_set
static int
gUSA_exchange_and_add (volatile int *mem, int val)
{
unsigned long dummy;
int result;
__asm__ (".align 2\n\t"
"la $8, 1f\n\t"
"move $9, $sp\n\t"
"li $sp, -16 # critical region start: rewind point #1\n"
"0: lw %0, (%2) # rewind point #2\n\t"
"move %1, %3\n\t"
"addu %1, %0, %1\n\t"
"sw %1, (%2)\n"
"1: move $sp, $9 # critical region end"
: "=&r" (result), "=&r" (dummy)
: "r" (mem), "r" (val)
: "memory", "$8", "$9");
return result;
}
|
Kernel Modification: MIPS 5900
--- linux-2.2.1_ps2/arch/mips/kernel/entry.S.orig Thu May 11 16:21:35 2000
+++ linux-2.2.1_ps2/arch/mips/kernel/entry.S Sun Aug 18 22:13:19 2002
@@ -49,7 +49,21 @@ EXPORT(handle_bottom_half)
b 9f
nop
-reschedule: jal schedule
+reschedule:
+ /* gUSA handling begin */
+ L_GREG t0, PT_R29(sp) # User stack
+ lui t1, 0xc000
+ sltu t2, t0, t1 # gUSA mark?
+ bnez t2, 1f
+ lw t1, PT_EPC(sp) # User PC
+ L_GREG t2, PT_R8(sp) # User T0: End point
+ sltu t3, t1, t2 # In the critical region?
+ beqz t3, 1f
+ /* Rewind */
+ addu t1, t0, t2 # User PC <- User SP + Endpoint
+ sw t1, PT_EPC(sp)
+ /* gUSA handling end */
+1: jal schedule
nop
EXPORT(ret_from_sys_call)
--- linux-2.2.1_ps2/arch/mips/kernel/signal.c.orig Wed Mar 21 02:24:48 2001
+++ linux-2.2.1_ps2/arch/mips/kernel/signal.c Sun Aug 18 19:59:36 2002
@@ -586,6 +586,16 @@ segv_and_exit:
static inline void handle_signal(unsigned long sig, struct k_sigaction *ka,
siginfo_t *info, sigset_t *oldset, struct pt_regs * regs)
{
+ if (regs->regs[29] >= 0xc0000000) { /* gUSA Handling */
+ int offset = (int)regs->regs[29];
+
+ /* Reset stack pointer: clear critical region mark */
+ regs->regs[29] = regs->regs[9];
+ if (regs->cp0_epc < regs->regs[8])
+ /* Go to rewind point #1 */
+ regs->cp0_epc = regs->regs[8] + offset - 4;
+ }
+
if (ka->sa.sa_flags & SA_SIGINFO)
setup_frame(ka, regs, sig, oldset, info);
else
|
Example of user space: StrongARM
static int
gUSA_exchange_and_add (volatile int *mem, int val)
{
unsigned long dummy;
int result;
__asm__ (
"add r0, pc, #16\n\t"
"mov r1, sp\n\t"
"mov sp, #-12 @ critical region start: rewind point #1\n"
"0: ldr %0, [%2] @ rewind point #2\n\t"
"add %1, %0, %3\n\t"
"str %1, [%2]\n"
"1: mov sp, r1 @ critical region end"
: "=&r" (result), "=&r" (dummy)
: "r" (mem), "r" (val)
: "memory", "r0", "r1");
return result;
}
|
Kernel Modification: StrongARM
--- linux-2.4.6-rmk1-np2-embedix-20011228-sl5000d-20020318/arch/arm/kernel/signal.c.orig
2001-06-26 16:15:41.000000000 +0900
+++ linux-2.4.6-rmk1-np2-embedix-20011228-sl5000d-20020318/arch/arm/kernel/signal.c
2002-09-06 22:11:22.000000000 +0900
@@ -478,7 +478,23 @@ static void
handle_signal(unsigned long sig, struct k_sigaction *ka,
siginfo_t *info, sigset_t *oldset, struct pt_regs * regs)
{
+ /* gUSA handling */
+#if defined(CONFIG_CPU_32)
+#define ARM_GUSA_MARK 0xf0000000
+#else
+#define ARM_GUSA_MARK 0x03c00000
+#endif
+ if (regs->ARM_sp > ARM_GUSA_MARK) {
+ int offset = (int)regs->ARM_sp;
+
+ /* Reset stack pointer: clear critical region mark */
+ regs->ARM_sp = regs->ARM_r1;
+ if (regs->ARM_pc < regs->ARM_r0)
+ /* Go to rewind point #1 */
+ regs->ARM_pc = regs->ARM_r0 + offset - 4;
+ }
+
/* Set up the stack frame */
if (ka->sa.sa_flags & SA_SIGINFO)
setup_rt_frame(sig, ka, info, oldset, regs);
--- linux-2.4.6-rmk1-np2-embedix-20011228-sl5000d-20020318/arch/arm/kernel/entry-common.S.orig
2001-07-23 14:34:01.000000000 +0900
+++ linux-2.4.6-rmk1-np2-embedix-20011228-sl5000d-20020318/arch/arm/kernel/entry-common.S
2002-09-07 11:14:33.000000000 +0900
@@ -53,6 +53,23 @@ slow: str r0, [sp, #S_R0+S_OFF]! @ retur
* "slow" syscall return path. "why" tells us if this was a real syscall.
*/
reschedule:
+ /* gUSA handling begin */
+#if defined(CONFIG_CPU_32)
+#define ARM_GUSA_MARK 0xf0000000
+#else
+#define ARM_GUSA_MARK 0x03c00000
+#endif
+ ldr r0, [sp, #S_SP] @ Get SP
+ cmp r0, #ARM_GUSA_MARK
+ bls call_resched @ SP <= ARM_GUSA_MARK
+ ldr r1, [sp, #S_PC] @ Get PC
+ ldr r2, [sp, #S_R0] @ Get R0 (end point)
+ cmp r2, r1
+ bls call_resched @ R0 <= PC
+ add r1, r2, r0 @ rewind point #2 = R0 + SP
+ str r1, [sp, #S_PC] @ Reset PC to rewind point #2
+ /* gUSA handling end */
+call_resched:
bl SYMBOL_NAME(schedule)
ENTRY(ret_to_user)
ret_slow_syscall:
|
The result of lmbench
SH-3
SolutionEngine SH7709A (with 64MB memory)
sh3 133MHz 64MB: kernel 2.4.18.superh + gusa / plain, NFS root
L M B E N C H 2 . 0 S U M M A R Y
------------------------------------------------------------------------
Processor, Processes - average times in microseconds - smaller is better
------------------------------------------------------------------------
null null open/
call Error I/O Error stat Error close Error
------ ------ ------ ------ ------ ------ ------ ------
gusa 2.147 0.001 4.381 0.002 47.862 0.351 106.654 1.438
plain 2.145 0.002 4.382 0.002 47.085 0.183 108.220 1.120
........................................................................
signal signal
select Error instll Error catch Error
------ ------ ------ ------ ------ ------
gusa 174.7 0.11 11.911 0.004 17.772 0.208
plain 174.4 0.30 11.909 0.001 16.886 0.005
........................................................................
fork exec shell
proc Error proc Error proc Error
------- ------- ------- ------- ------- -------
gusa 4497.9 3.35 19212.6 9.92 71958.6 39.06
plain 4528.3 3.61 19753.3 493.85 73953.3 1946.68
------------------------------------------------------------------------
Context switching - times in microseconds - smaller is better
------------------------------------------------------------------------
2p/0K 2p/16K 2p/64K
Error Error Error
------ ------ ------ ------ ------ ------
gusa 8.29 0.592 391.41 1.279 1217.76 0.860
plain 7.67 0.357 393.97 0.301 1217.80 1.406
........................................................................
8p/0K 8p/16K 8p/64K
Error Error Error
------ ------ ------ ------ ------ ------
gusa 21.22 1.631 407.25 1.631 1285.42 1.308
plain 19.99 2.860 402.61 2.860 1287.35 1.475
........................................................................
16p/0K 16p/16K 16p/64K
Error Error Error
------ ------ ------ ------ ------ ------
gusa 27.10 1.253 418.95 0.379 1297.86 0.347
plain 25.86 0.928 418.31 0.623 1297.31 0.765
========================================================================
|
SH-4
SolutionEngine SH7750S
sh4 200MHz 64MB: kernel 2.4.18.superh + gusa / plain, NFS root
L M B E N C H 2 . 0 S U M M A R Y
------------------------------------------------------------------------
Processor, Processes - average times in microseconds - smaller is better
------------------------------------------------------------------------
null null open/
call Error I/O Error stat Error close Error
------ ------ ------ ------ ------ ------ ------ ------
gusa 1.143 0.000 2.709 0.044 40.762 0.453 69.128 1.117
plain 1.143 0.000 2.772 0.121 37.264 0.324 67.690 0.975
........................................................................
signal signal
select Error instll Error catch Error
------ ------ ------ ------ ------ ------
gusa 99.1 2.05 9.390 0.041 20.944 0.116
plain 105.4 9.43 9.604 0.061 20.542 0.244
........................................................................
fork exec shell
proc Error proc Error proc Error
------- ------- ------- ------- ------- -------
gusa 1981.6 13.59 9825.2 18.22 41592.9 57.59
plain 1945.4 26.72 10464.7 358.93 44617.7 1490.07
------------------------------------------------------------------------
Context switching - times in microseconds - smaller is better
------------------------------------------------------------------------
2p/0K 2p/16K 2p/64K
Error Error Error
------ ------ ------ ------ ------ ------
gusa 7.72 0.708 77.93 0.640 239.31 0.553
plain 9.28 1.760 78.30 0.867 238.32 1.164
........................................................................
8p/0K 8p/16K 8p/64K
Error Error Error
------ ------ ------ ------ ------ ------
gusa 17.98 0.545 129.22 0.545 390.09 0.191
plain 18.58 0.286 130.40 0.286 392.51 1.499
........................................................................
16p/0K 16p/16K 16p/64K
Error Error Error
------ ------ ------ ------ ------ ------
gusa 38.09 0.348 144.11 0.129 394.79 0.263
plain 39.49 0.228 145.63 0.617 398.11 3.186
========================================================================
|
|
|
|
